Recap
Since September 2021, we have working on an experimental project called TorchDynamo. TorchDynamo is a Python-level JIT compiler designed to make unmodified PyTorch programs faster. TorchDynamo hooks into the frame evaluation API in CPython to dynamically modify Python bytecode right before it is executed. It rewrites Python bytecode in order to extract sequences of PyTorch operations into an FX Graph which is then just-in-time compiled with an ensemble of different backends and autotuning. It creates this FX Graph through bytecode analysis and is designed to generate smaller graph fragments that can be mixed with Python execution to get the best of both worlds: usability and performance.
If you are new here, the (recently rewritten) TorchDynamo README is a good place to start, you can also catch up on our prior posts::
- Update 1: An Experiment in Dynamic Python Bytecode Transformation
- Update 2: 1.48x geomean speedup on TorchBench CPU Inference
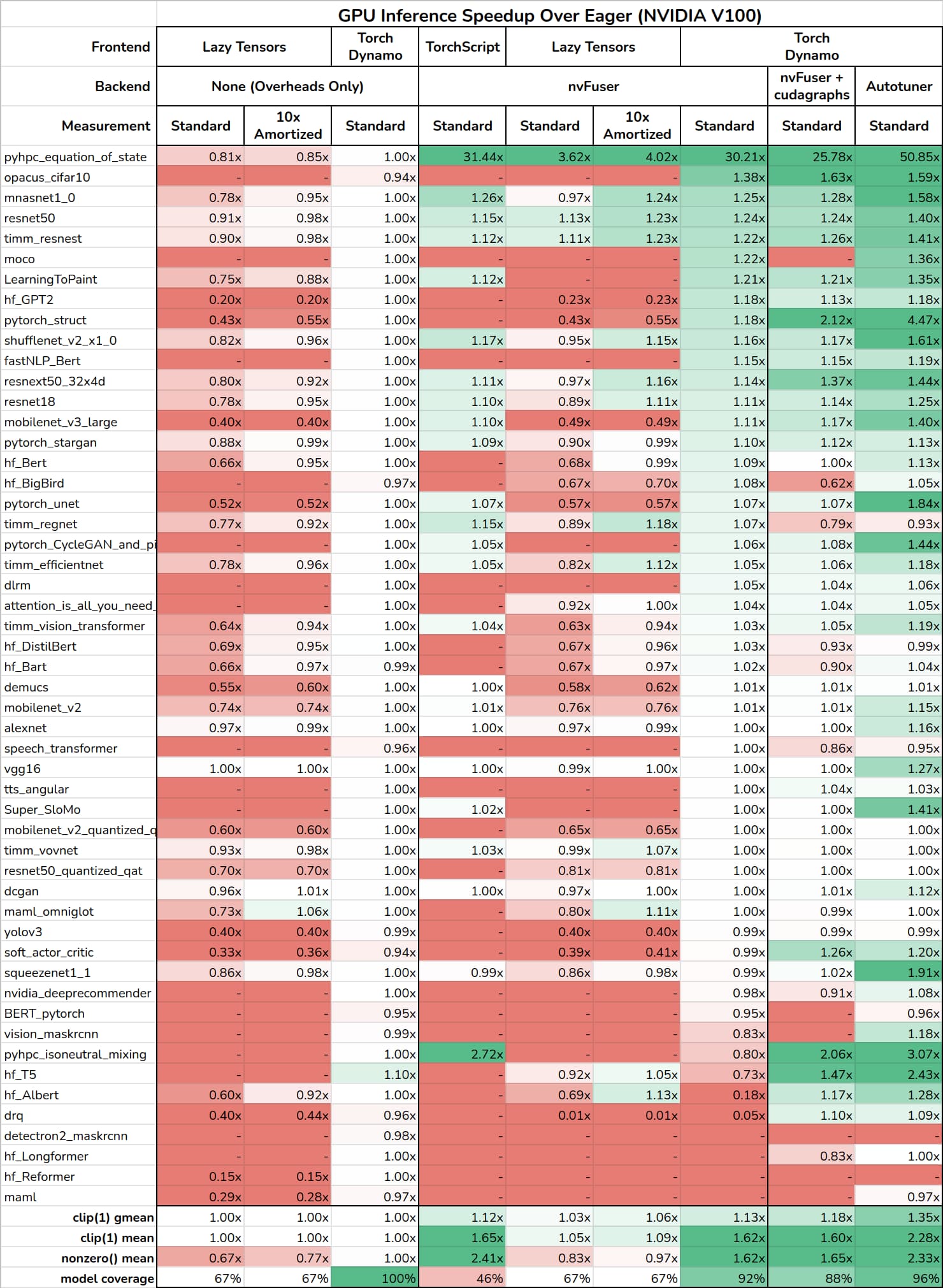
- Update 3: GPU Inference Edition
TorchDynamo Progress
Since last time the focus has been on improving Python capture, performance, documentation, and being more selective about the type of ops captured. The prior version of TorchDynamo would capture a lot of things most backends could not support, and the bottleneck was often backends rather than TorchDynamo. Frequently TorchDynamo would capture a graph that only eager mode supported. The latest version of TorchDynamo is much more picky, and will break graphs more frequently to increase the chance backends will work. Additionally, TorchDynamo now includes dynamic functionalization, operator normalization, alias analysis, shape analysis, and specialization passes that allow it to normalize graphs and provide easier to optimize graphs to backends.
Comparing to Lazy Tensors
The most similar effort to TorchDynamo is Lazy Tensors Core. Both systems aim to dynamically capture unmodified PyTorch programs, however they differ in approach. Lazy Tensors operates at the dispatcher level and captures ops by deferring evaluation to build up a graph. TorchDynamo operates at the Python frame level as a JIT compiler. TorchDynamo converts a frame once, just-in-time the first time it is called with novel input types, while Lazy Tensors recaptures every time.
The attached data compares the performance of Lazy Tensors and TorchDynamo on the same hardware: NVIDIA V100; and latest code version. For Lazy Tensors we provide two ways to measure: “Standard” measurement measures the same way as other systems, taking the median execution time of 100 runs normalized to eager mode; “10x Amortized” overlaps the added latency of Lazy Tensors across multiple executions by running 10 times before synchronizing and represents a throughput-bound best case.
The first three columns compare the two systems with no backend in order to measure capture overheads alone. TorchDynamo runs the captured FX graphs unoptimized in Python, while Lazy Tensors runs using unoptimized Simple Executor in TorchScript. One can see that TorchDynamo has close to zero overheads on average, and in the worst case runs at 0.94x speed (6% slower than eager). Lazy Tensors (for the subset of models it works on) runs on average at 0.67x speed when measured the same way as TorchDynamo and 0.77x with amortization. In the worst case Lazy Tensors runs at 0.20x (5x slower than eager). The slowdown in Lazy Tensors comes from a combination of missing op support causing eager fallbacks, and inefficient tracing. The missing ops are going to be completed in a matter of weeks, and efficient tracing is a major focus for the team now. Overall, the comparison shown is not representative of lazy tracing as a technique, but of an incomplete/unoptimized system.
The next four columns compare TorchScript, Lazy Tensors, and TorchDynamo all using the same nvFuser backend. This is a good chance for an apples-to-apples comparison and to see if an optimizing backend can offset the slowdowns introduced by capture. The main issue that the TorchScript numbers show is usability, TorchScript works on less than half of models, though, when it works it can provide speedups. Lazy Tensor Core only provides speedups on 3 models (14 with amortization), and in the rest of cases generates slowdowns or errors. TorchDynamo with an nvFuser backend works on 92% of models and provides the best geomean speedup of the nvFuser frontends.
The final two columns show TorchDynamo with additional backends: nvFuser+cudagraphs and the TorchDynamo Autotuner (described in the prior posts, with some minor improvements). These backends are included to put the other results in context of what additional speedups are possible. We can see that adding cudagraphs in addition to nvFuser improves the overall geomean speedup, but is not the best choice in all cases. The TorchDynamo Autotuner, by using an ensemble of different backends, is able to provide a much larger geometric mean speedup than any other approach tested.
TorchDynamo Graph Sizes
A key difference TorchDynamo has is that it works with eager mode, rather than trying to replace it. This means that it frequently breaks graphs or falls back to eager mode in a transparent low-overhead way. For CPU/GPU, this is fine and cheap because we have a fast eager mode to fall back to. For adding new hardware backends to PyTorch, this could present a bigger problem. Some inflexible hardware or compilers might have large performance cliffs if they do not get whole program graphs.
Let’s first look at how frequently TorchDynamo falls back to eager. Overall TorchDynamo captures 83% of ops (measured by mean time):
- For 33 benchmarks, over 99% of ops are captured and for 27 TorchDynamo provides a single whole-program graph
- For 10 benchmarks, 70% to 98% of ops are captured
- For 4 benchmarks, 1% to 69% of ops are captured
- For 4 benchmarks 0% of ops are captured.
Next let’s look at number of graphs (measured by dynamic calls, not static compiles):
- 27 benchmarks have 1 graph call
- 9 benchmarks have 2 to 10 graph calls
- 10 benchmarks have 11 to 100 graph calls
- 5 benchmarks have >100 graph calls
The average graph has 15.4 ops on and the largest graph is 1391 ops.
Conclusions
The data presented here shows that TorchDynamo currently has a big advantage both in performance and usability, primarily driven by its close-to-zero overheads and fast eager interoperability. Lazy Tensor implementation hasn’t been optimized for overheads so far, the team is currently making a big push to try to improve these numbers. We expect to see the updated results based on this effort soon.
A key open question is: do these results translate to other hardware that is much less flexible than CPU/GPU. Hypothetically, one could imagine hardware/compilers that generate large enough speedup from big graphs that it outweighs the costs (either in overhead for Lazy Tensors or usability for TorchScript) required to get them. However, we do not currently have examples of a PyTorch backend like this, and it is something we need to find and measure empirically.
It is an exciting time, and we are seeing a lot of forward progress in this area. I specifically want to call out a few interesting ongoing explorations:
- @anijain2305 is exploring a TorchDynamo + AOT Autograd integration to provide training support in TorchDynamo by using AOT Autograd as a backend.
- @shunting314 is exploring a TorchDynamo + Lazy Tensors integration to allow access to Lazy Tensor backends (like XLA) from TorchDynamo.
- @desertfire is working on a new approach to caching that may dramatically improve the overheads of Lazy Tensors.