This is a little more than two week’s worth of updates, covering PSC week, Edward on vacation and July 4th holiday.
Dynamic shapes by default is landed. To be clear, this is “automatically enable dynamic shapes if recompiling due to size changes.” Most models running PT2 should not see any difference, as they are static already. If your model has dynamism, expect dramatically lower compilation times at the cost of some E2E performance. There may be performance regressions, please file bugs if you encounter any. You can use TORCH_LOGS=dynamic to diagnose if dynamic shapes is doing something. Check also the Meta only post
Internal telemetry for dynamic shapes.Add signpost_event to dynamic_shapes adds a hook which we use internally to record all uses of dynamic shapes. You can check if dynamic shapes was actually used when free_symbols is non-zero.
Roadmap review for H2 2023. We had roadmap review for PyTorch teams last week. Dynamic shapes presence on the roadmaps looks like this: (1) we have a bunch of internal enablement plans which require dynamic shapes to be well supported, make sure we are on point here (Meta only), (2) we’re really interested in getting good inference performance on LLMs comparable to SOTA, e.g., llama (there’s some kv-cache / cuda graphs pieces here), (3) there’s still jagged/nested tensor work to do. On a more atomic level, the infra investments that dynamic shapes need to make are probably (a) two level guards for backwards shape guards, (b) improved accuracy/compile time debugging tools, (c) more aggressive symbolic reasoning enabled by translation validation, (d) obvious inductor compilation perf improvements, e.g., from split reductions, (e) Unbacked integers for eager mode. I’d also like to finally get vision_maskrcnn and detectron2 working on PT2, but LLMs take priority over this.
Which operators specialize their inputs? In the old days, dynamic shapes enablement would typically fail because of missing meta functions. These days, things usually don’t fail, but you may end up having specialized and recompiling anyway. @anijain2305 has been working on sweeping operators to find out which arguments get specialized, to help folks have a better understanding of what will be dynamic versus not.
vision_maskrcnn went back to failing, seems flaky.
eca_botnext26ts_256 and mobilevit_s timed out due to translation validation being enabled. #104654 fixed it (to be visible in next perf run.) Compilation time increase also appears to be due to TV.
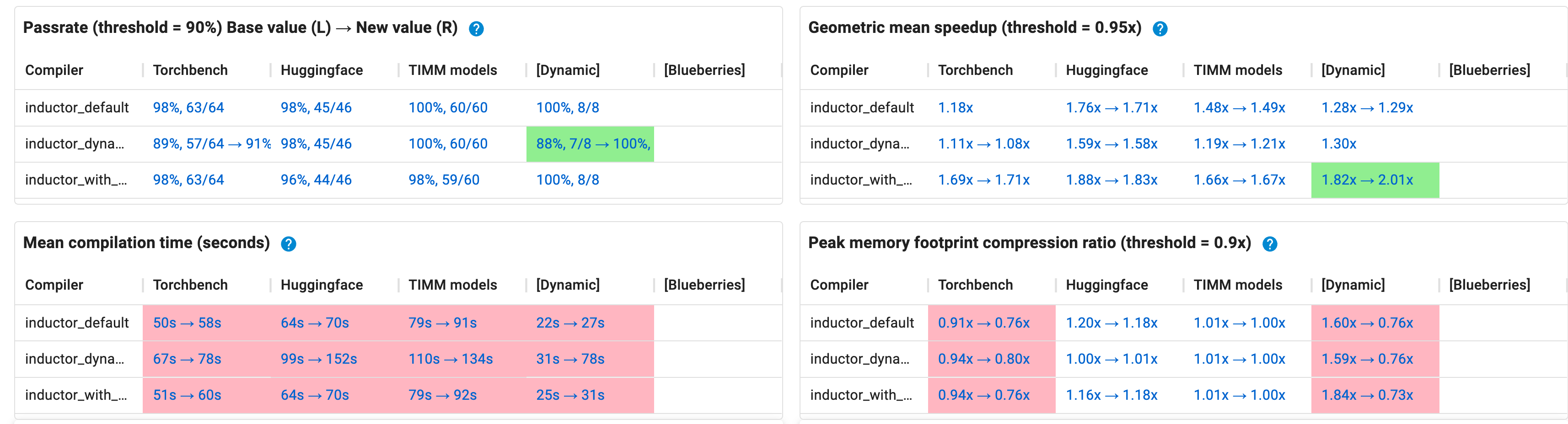
Dynamic shapes now support mode=“reduce-overhead” (CUDA graphs). Conventional wisdom was that dynamic shapes are incompatible with CUDA graphs, because any given CUDA graph recording can only work for a single static shape, and CUDA graphs requirement of hard coded memory addresses means that each CUDA graph takes up quite a lot of CUDA memory. However, this conventional wisdom is wrong: (1) multiple CUDA graphs can share the same memory pool, as long as you don’t have any live tensors from one pool to the next (this is precisely what CUDA graph trees by @eellison implements), and (2) recording a CUDA graph is much, much cheaper than running the entire PT2 compilation stack, so it is profitable to compile a dynamic program once and then CUDA graph it multiple times. https://github.com/pytorch/pytorch/pull/105064 realizes these gains and switches our dynamic shapes benchmark configuration to use CUDA graphs, resulting in hefty performance gains with only a modest increase in compile time. Importantly, these benchmarks cover our _generate inference benchmarks, which actually make use of multiple sizes as sequence length varies. There’s more to be done here: our memory usage for this use case can be suboptimal, because the caching allocator doesn’t know that it’s OK to waste space for small allocations by fitting them inside larger allocations for a larger dynamic size. We also observed that folks using this CUDA graphs trick tend not to generate CUDA graphs for every size, but instead prefer to linearly sample sizes and pad; we should make it easier to do this (perhaps with a padding tensor subclass.) One cool result is a 6x performance improvement on cm3leon, a newly announced multi-modal model from Meta AI.
New API: torch._dynamo.maybe_mark_dynamic.Add torch._dynamo.maybe_mark_dynamic lets you suggest that we should try compiling a tensor dynamically, but doesn’t raise an error if it gets specialized (unlike mark_dynamic).
Infer valid input sizes from programs. Horace has wanted this for some time, and with Yukio’s recent Z3 translation validation work landed, it turned out to be pretty easy to write a PoC to exhaustively search the space of valid inputs, using guards to turn us away from portions of the space we’ve seen before. Check it out at dinfer.py · GitHub. If anyone is interested in productionizing this, it would be a neat little project to (1) put this code in PyTorch and put a nicer API on it (note that as written, you have to specify the input dimensions and dtypes of input tensors, so you’ll need to figure out a good way of specifying or inferring this info), (2) improve the solving code to minimize the generated sizes for an equivalence class, and (3) use it for something cool; e.g., you could use it to automatically generate sample inputs for OpInfo tests. Tag me (@ezyang) as reviewer if you send a PR!
Transmute refined SymInt into int makes it more likely you’ll get an int rather than a SymInt if the SymInt got specialized into a constant. This sometimes caused some bugs with downstream components that can handle SymInt but choke on int.
Inductor backend for CPU inference extremely slow - this bug actually seems to be fixed on main thanks to dynamic shapes. Moral of the story: if you want dynamic shapes, use a nightly! We have soooo many improvements.
Now passing: hf_Longformer (this used to fail with ValueError: Cannot view a tensor with shape torch.Size([4, 12, 1024, 513]) and strides (6303744, 513, 6156, 1) as a tensor with shape (48, 4, 256, 513), this is thanks to Brian Hirsh finally landing his AOTAutograd longformer fix), vision_maskrcnn (flaky), eca_botnext26ts_256 and mobilevit_s (used to timeout; maybe the speedup from CUDA graphs was enough to get it under the timeout again)
Now failing: DebertaV2ForQuestionAnswering (failing accuracy due to cudagraphs, failing on inductor_with_cudagraphs too), cait_m36_384 (OOMing on accuracy due to increased CUDA graph memory usage)
Speedups: The majority of our speedups are due to the enablement of CUDA graphs for dynamic shapes. Some notable models and their speedups: BERT_pytorch (1.7698 → 3.3071), hf_GPT2 (1.7728 → 2.0056), basic_gnn_gin (1.3151 → 2.4841). The improvements on HF and TIMM models are much more modest since these are not super overhead bound models. Note that these numbers are still behind inductor_with_cudagraphs, because we are still losing some optimizations from running the PT2 compiler stack without static shapes.
Slowdowns: dlrm (infra failure due to cudagraphs, failing on inductor_with_cudagraphs too), hf_T5 (2.0252 → 1.8939, oddly enough–could this be due to memory pressure? But even more weirdly, hf_T5_large imporved perf)
Comptime/Memory: By in large compilation time did not increase, but for our training setup this is expected as we only actually run at one batch size, so you are simply measuring the cost of a single CUDA graph recording. As expected, memory compression ratio gets worse, due to standing allocation from CUDA graphs.
Speedups: torchbench numbers are actually a huge mixed bag. Here are some of the wins: BERT_pytorch (2.2317 → 2.4529), basic_gnn_edgecnn (1.7809 → 1.8732). Note that for some reason many of the GNN variants are failing performance on inference (but not accuracy), cm3leon_generate (1.3037 → 5.7822, WOW! This is consistent with some perf analysis Armen and I did months ago, where I concluded that cm3leon was hella overhead bound), hf_T5_generate (2.2619 → 8.2081), hf_T5_large (3.1690 → 5.1747)
Slowdowns: A lot more models did worse with CUDA graphs enabled, including LearningToPaint (1.9209 → 1.6812), resnet18 (1.7779 → 1.4028), shufflenet_v2_x1_0 (1.9882 → 1.6010), squeezenet1_1 (1.8625 → 1.0040), yolov3 (2.0997 → 1.8843). It’s not entirely clear what’s going on here, but we will note that there was sizable dip in CUDA graphs performance without dynamic shapes too this week on torchbench. There is an across the board performance regression on TIMM models (and a slight regression on HuggingFace too.)
Comptime/Memory: Comptime generally got worse across the board, but not too much worse. Particularly notable are the generate models: hf_T5_generate (881 → 1032), cm3leon_generate (131 → 203). CUDA graphs is not free, but given that we’re running at much more than two sequence lengths, you can see the bulk of the compile cost is the PT2 stack. For the most part, memory usage stayed fairly stable, interestingly enough.
What’s next?
I think I want to investigate the memory planning situation with CUDA graphs a bit more; I also think it’s a good time to teach Inductor how to deal with data-dependent ops (without having to graph break on them.)
Whole model compilation for sparse architecture in recommendation models.@anijain2305 has been looking at improving the ability to slap torch.compile on an arbitrary function and have it just work. One of the more challenging situations is when we try to compile the sparse architecture of recommendation models; e.g., code that interacts with [torchrec.sparse/(torchrec/torchrec/sparse at main · meta-pytorch/torchrec · GitHub). In one example, a KeyedJaggedTensor is being compiled, but it contains a list of 500 integers, each of which varies over time and participates in many guards. This is a worst case scenario for dynamic shapes compile time. However, we are also running into lots of graph breaks, which are resulting in us trying to compile smaller fragments than we should. There will be a mix of fixing graph breaks (some of them are due to data dependent output size operators like nonzero–time to fix this!) and otherwise figuring out what else needs to be done.
Across the board timm improvement is due to reverting regressing PR from last week https://github.com/pytorch/pytorch/pull/105102 (bucketization related). This also explains the slight boost in torchbench numbers.
CUDA graphs memory planning is lower priority for now (@eellison may take a look, but higher priority is actually being able to turn on CUDA graphs in prod situations; a big problem here is when we fail to compile the entire extent of the model, causing CUDA graphs to increase overall memory usage.) It looks like we definitely need data-dependent op support in inductor though, based on sparse arch investigation.
Data dependent shape support in Inductor. I got an end to end PoC of a pointwise and then reduction with hacks working in Inductor: gist:1293a41299604c44310341b7540eabcb · GitHub The main gaps: (1) optional optimizations failing to retrieve hints (Triton size hints (pick 8192 to prevent the block size from shrinking), multiple of 16 hints (pick something not multiple of 16), 32-bit indexing), (3) buffer reuse (key’ing on the str rep is fine, use sympy_str), (4) updating wrapper codegen to create bindings to i0 variables. In general, it seems it’s pretty useful to have accurate maximum size information, for which ValueRanges is an incomplete fix because we don’t support symbols (s0) in bounds. Another trick we plan to implement is a special irrefutable guard, where if we guard on an unbacked symint, we instead just assume it is True and add a runtime assertion. One question is whether or not we always can get dynamic shapes working no matter what. It seems that in Inductor, we usually can just turn off optimizations to avoid guards. So it seems we just need to get host-side torch.cond working to handle everything else. Some fixes for these are in: If we can’t statically prove 32-bit indexing OK, only add guard if hint exists, Provide a refined upper bound for nonzero when original numel is static
An initial plan for KeyedJaggedTensor. After studying some of the models that use KJT and trying to get export working on them, here are some of the initial findings:
You can remove the list of integers from KJT before tracing a model, which will cause the model to perform a data-dependent access to populate these integers as unbacked integers. However, when we try to use these integers to do a tensor_split, we immediately hit guards we cannot prove. The guards should be provable via sum(lengths) == values.shape[0] but our symbolic reasoning is not strong enough. These guards are for errors, so they should be bypassable by irrefutable guards (guards which, if they fail, imply you would have errored anyway. In this case you can convert the guard into a runtime test.) This is worth pursuing further. In any case, you expect to have 500 unbacked symints, symbolic reasoning must be fast enough to deal with it.
If you don’t remove the list of integers, you need some way to prevent them from 0/1 specializing. In export, you can simply require every sparse feature be populated to size 2 and hope it generalizes to 0/1. In eager, we probably will just have to specialize KJT to treat these integers specially. Big benefit to this strategy is you’re not hard-blocked on guards on unbacked SymInts, since there’s always a hint; don’t need any sum(lengths) reasoning since guards are discharged by checking the underlying values. Cannot actually do this in export because export does not support SymInt inputs–I plan to fix this.
Export with KJTs doesn’t work because KJTs are not a supported input. Direct fix Add pytree support to KeyedJaggedTensor by ezyang · Pull Request #1287 · meta-pytorch/torchrec · GitHub; indirect fix is rewriting the export calling convention from pytree specs to a dictionary of “FQN” (Source.name()) really to Tensor. In that case, to pass a KJT named id_list_features, you would actually pass three tensors, id_list_features._values, etc.
More details at Meta-only doc (sorry, non-public due to details about Meta prod models).
Translation validation bisection. We had a case of hint disagreeing with sympy simplification in internal; we’ve also had instances of this in open source, see [https://github.com/pytorch/pytorch/pull/101173](integer and real equality). Yukio is thinking of implementing a bisection mechanism for translation validation, so we can find the first guard that actually caused a correctness problem.
Export for QAT. QAT wants to do whole-graph transformations on a pre-autograd FX graph. Export sort of supports this with pre_dispatch export. What is likely going to happen is this turns into the IR format that export is going to use. Pre-autograd functionalization is unlikely to happen; you only get some mild normalization. Still unresolved how to work this into the overall QAT workflow API, since export isn’t really keen on exposing this mid-point IR (which is kind of incoherent.)
More on KJT/torchrec. I had a nice discussion with Dennis van der Staay about torchrec and work on sparse arch. Some new information: (1) this workstream is almost certainly going to involve distributed later, because applying PT2 to post-torchrec sharded models is going to involve tracing past communication primitives–this also implies I’m going to want to get FakePG working on torchrec, (2) working on unit tests should be a pretty good idea, but there’s still some basic infra work to do (laid out last week), (3) not really expecting concrete performance improvements as sparse arch is going to be typically communication bound, so this is a mostly “we think this is promising, and the investment is not too big, because we’ve already done so much with dynamic shapes so far.”)
Pre-dispatch export. We’ve agreed to allow QAT to short-term publish a new export interface that produces a pre-dispatch FX graph with ATen operators which is suitable for graph transformations and training. The long term goal will to be have pre-dispatch functionalization which is the invariant the export team wants to allow this to be worked into torch.export proper. Pre-dispatch will generate an ExportedModule so that the APIs match.
Fake export. Export now supports exporting entirely fake modules/inputs. This means to export a model you don’t have to actually load its weights into memory; you can load it in a fake mode and still export it. This means we have some delicate code in Dynamo for dealing with two concurrent fake modes (but it’s not so bad: the outer fake mode is typically disabled while we do Dynamo analysis.) Only ONNX supports torch.load’ing models in fake mode at the moment.
Improved user stacks in Dynamo.torch._guards.TracingContext.extract_stack() now always accurately reports a user stack from anywhere in Dynamo, and we reliably use it for reporting real stacks for exceptions (previously, they used an entirely different mechanism.)
Improved error messages for non-local inputs in export. See Improve error message when export encounters non-local input for the details. This isn’t complete; follow through is also to make this work for outputs, and also work a little harder with the pytree representation (probably this week.)
Dynamo change in attitude. Many folks are concerned that Dynamo is just “endless” bugs. I pitched Animesh and Voz on a new attitude to fixing Dynamo bugs, which is that we should imagine the platonic ideal implementation of Dynamo as a faithful reimplementation of CPython in Python. Then, fixing a bug should not just be moving code around to fix a particular problem, but instead improving the local vicinity of code to bring it closer in line to this ideal. An example I used a lot explaining this was dict.keys support (bug fix is changing its type from tuple to set; real fix is to accurately model dict views.) To do this well, you need to regularly look at CPython code, and Dynamo may need to grow some new abstractions (perhaps a proper implementation of Python’s object model, Python traceable polyfills).
The big perf increase in torchbench is due to maml getting removed from the benchmark set (it slows down a lot under PT2 and was depressing the score). clip, hf_Whisper, llama_v2 are new models added thanks to @msaroufim !
What’s next?
There are a lot of things that need doing
Finish overhauling export input/output pytree matching (probably not dumping the pytree in/out spec, but I think if we tree_map into positional identifiers we can reliably detect KJT missing situations)
I’m trying something a little different, expanding the update to cover a wider variety of topics beyond dynamic shapes, mostly centered around things that I personally have involvement in (this is a lot of things, so you should be getting pretty good coverage this way!)
Benchmarking
Inductor CI/perf is upgraded to CUDA 12 / gcc 9. This doesn’t seem to have any appreciable effect on perf, but we did it so we could do the next item.
torchrec_dlrm is back. They were disabled a few months ago because of fbgemm nightly related flakiness. The flakiness has been resolved by building fbgemm/torchrec from source in the Docker image. These are now installed as part of the general torchbench installs, and should help some of the work we are doing on jagged tensors (since many important operators are currently implemented in fbgemm).
Algorithmic efficiency. Frank Schneider posted about how PyTorch was slower than JAX in their upcoming algorithmic-efficiency benchmark suite. A bunch of us, spearheaded by @msaroufim, jumped in to take a look at what was going on. Status updates at https://docs.google.com/document/d/1okqKS32b0EhWQSFFoSV6IjGlYM4VhNYdxBPjdlFIw5w/edit (Meta-only). I personally have an interest in the dlrm side of things, since I’ve been working on sparse arch recently; after fixing some mild bugs, I was able to show parity on criteo1tb dlrm between PyTorch nightly and JAX on an A100x8 (PyTorch score: 7703.403180360794, JAX score: 7703.041719198227), although the number of evals varied, so I’m not sure if this a threat to validity. Unfortunately, this does not necessarily help their problem, which was an OOM. To make further progress on this, we may need some tools to help us understand why torch.compile memory usage is higher.
Export
Pre-dispatch export, part 2. We had more discussion about pre-dispatch export in the Friday export meeting. @suo in particular was arguing that from a frontend perspective, it would make more sense to export pre-dispatch IR by default, and have the further post-dispatch lowerings be an extra pass on top that is opt-in by backends. One of the identified barriers to doing this is pre dispatch functionalization; the other is nondifferentiable decomps. nkaretnikov is going to take a look at core_aten_decompositions to see which of these are differentiable and which are not. In other news, torch.export is going platinum https://github.com/pytorch/pytorch/pull/106904/
dim order coming to Tensor. We probably should have added this API a long time ago, but export really wants this on Tensor so in it goes. https://github.com/pytorch/pytorch/pull/106835
Distributed
Tracing FSDP.@voz wrote a post https://fb.workplace.com/groups/2917693311835451/ (Meta-only) about the state of tracing FSDP in Dynamo. The key info is that on a branch, he can trace everything through and get identical results on a single forward-backward to eager. There’s a lot of fixes that need to land to main; from his post:
The value of various small changes to FSDP to make this work vs adding fixes in dynamo (Pretty easy, preferring dynamo ofc but for some mostly no op shuffling, we do FSDP as well)
TypedStorage - is it tensor-like/tensor-associated enough to go in the graph? Do we need to add some ops for doing tensor typed storage data ptr comparison / checking free, etc?
Working through the cudastream story, in particular around wait_stream and such
Lot’s of little bug fixes here and there
Coverage for missing comparisons, bytecode ops, general coverage gaps like attr access on FSDP modules, setting data on a tensor, etc.
pytrees slow again for DTensor. Junjie and Rodrigo have been trying to improve DTensor’s eager perf, and we spent the first half of composability sync talking about it. Rodrigo had a hack to pre-compile pytree applications into Python code but apparently this doesn’t help that much: gist:5427cabfab6421d4e104905345f94a50 · GitHub . Another suggestion from the meeting was that after Brian’s subclass supports lands, maybe you could torch.compile each op individually with backend=“eager”.
Custom ops. Richard tells me he is going to add a class-based API for custom ops, to make it easier to define everything all in one place. More on this soon I assume!
SkolemSymNodeImpl.@jw3468 is going to make size() work on jagged tensor by introducing a new concept to SymInt provisionally called SkolemSymNodeImpl. This is a special SymInt which is not symbolic (it can show up in eager mode) but only compares equal to itself (aka is a skolem variable). We will use this to represent jagged dimensions. All jagged tensors that have the same offsets tensor get assigned the same skolem variable, if you have different offsets tensors you can’t add them together because their skolem variables don’t match. More details at https://docs.google.com/document/d/1e-R_818YA4VlVTlozu5eyzRIV6TzyvSPDm9DMEw_4xg/edit (Meta-only)
Time to get rid of functional VariableTracker? VariableTracker in Dynamo is an immutable data structure: when a mutation happens, you allocate a fresh VariableTracker and then replace old VariableTrackers with the new one. This is because we have checkpointing functionality that is used to rewind old VariableTracker. However, this is a bit of pain from the modeling side, as every Python data structure has to be reimplemented to have purely functional operations. An alternate design is to allow direct mutation of VariableTrackers. To do checkpoints, we simply restart Dynamo analysis to “go back in time” by stopping execution at the point where we would have checkpointed (a deepcopy could also work, though I’m not a fan.) Speculate subgraph would be implemented by simply denying all mutations or doing some crazy thermometer continuation thing. This would help make Dynamo more metacircular and reduce the work needed to support new container types, of which we often need to support a lot.
Dynamic shapes
expect_true irrefutable guards. I talked through this in the last 20min of composability sync. Check https://github.com/pytorch/pytorch/pull/106720 ; this is enough to make splits on unbacked SymInts work.
Boolean masking, at last.@yanboliang is looking into a pre-autograd FX transform that replaces boolean mask updates with torch.where calls. One annoying detail is how to deal with Dynamo tracing the boolean masks in the first place, when Inductor can’t deal with boolean masks if you can’t eliminate them? Our idea, in lieu of fixing Inductor to work with data-dependent shapes (which we are working on), is to attempt to eliminate all data-dependent ops in a pre-dispatch pass, and if it is not possible, restart Dynamo analysis saying “you need to graph break on this op next time.”
Notable fixes.
SymInt’ify tile. This one needed for algorithmic-efficiency criteo1tb dlrm.
Some accuracy regressions. torchbench: hf_BigBird, vision_maskrcnn (flaky). It’s not clear what broke hf_BigBird; possibly the CUDA 12 upgrade. Need to investigate. AlbertForQuestionAnswering improved accuracy!
The huge perf improvement across the board is thanks to Peter Bell’s work https://github.com/pytorch/pytorch/pull/106747 optimizing split reductions. This is not full runtime split reductions: instead Peter uses whatever the hint was at the time we compiled to plan the split reduction, and then we use it for all subsequent runs. This makes it more important to warm up Inductor with the “right” size hint to start; see also Padded tensor subclass · Issue #105325 · pytorch/pytorch · GitHub ; there was also another user complaining about other cases where we made suboptimal decisions if the first kernel we compiled with wasn’t representative
A lot of change on the last day; some improvements and some regressions (but mostly regressions). Maybe CUDA 12 update related, need to check. hf_BigBird also failing here too. RobertaForQuestionAnswering failing accuracy now
Trying to understand how to read PT2 logs? Check out Logging docs - Google Docs for some quick orientation. (In other news, guards logging this week has been improved to show you which line of user code caused a guard to be added! Take a look and don’t be afraid to give feedback on it.)
Have you ever wanted to store lots of tracebacks for logging/debugging purposes, but were afraid to do so by default because it might be too expensive to do so? There is a new class in torch.utils._traceback called CapturedTraceback which makes it extremely fast to save a Python traceback (something like 20x faster than running a full traceback.extract_stack()), so it should change the calculation about whether or not you are willing to store tracebacks by default. We have already used this to keep fine-grained information about guard provenance to start. Note that CapturedTraceback DOES hold references to code objects, and these references can cause cycles (because of co_extra), so good practice is to make sure you clear these traces once you know you no longer need them.
I spent some time debugging reference cycles this week (due to CapturedTraceback), and Alban pointed me at objgraph for visualizing references/referents. It’s pretty cool, you should definitely check it out.
We are continuing to do a terrible job at not causing reference cycles in our compiler data structures. Folks have noticed that we leak compiled models even when the model objects are deleted. This generally emerges when a reference cycle goes through a non traversable object (C++ shared references or co_extra on code objects); the result cannot be deallocated unless we explicitly break the reference cycle, which we generally do not do. Animesh is going to take a whack at the model finalization problem. On the bright side, Animesh did push a fix for a long standing bug [dynamo][eval_frame] Set destroy_extra_state deleter as part of co_extra by anijain2305 · Pull Request #107117 · pytorch/pytorch · GitHub related to code object deallocation (admittedly rare, but it can happen);
Yidi Wu wanted to know if we could guard against backends changing https://github.com/pytorch/pytorch/pull/107337 so you don’t have to call dynamo.reset() anymore. The motivation was to allow people to seamlessly use eager backend along side their compiled backend. Difficult!
Efficient transformer inference needs in-place scatter, being worked on at https://github.com/pytorch/pytorch/pull/106192 This is not so easy to do because we generally don’t like dealing with mutation in Inductor but Horace thinks he has a plan.
When doing passes on FX graphs, it can be annoying to keep fake tensor metadata up-to-date. Horace is looking into some incremental rebuilding of the metadata, stopping re-propagation once you notice that the fake tensor lines up with the old values.
Distributed
Handling backward hooks in Dynamo is kind of difficult. There is a discontinuity between hooks on inputs and hooks on intermediates; hooks on intermediates, in particular, have to somehow be reflected in whatever graph gets differentiated by autograd, but at the same time these hooks may have arbitrary Python bits that need handling by Dynamo. It seems the problem is made easier if we have combined forward-backward tracing in Dynamo, at which Dynamo knows enough about the backward structure to bypass AOTAutograd entirely. It might also be possible to just do cuts prior to going to AOTAutograd, which will impede optimization. It might be possible to bypass this problem for FSDP if hooks are only on parameters and outputs. Lots of difficulties…
dlrm is now passing on dynamic shapes which is cool. RobertaForQuestionAnswering was fixed (not clear what fixed this; it’s in the 35cca799ff42182a1b7f1ee4d0225ee879b7c924..384e0d104fd077d31efafc564129660e9b7a0f25 range). Some other wins (and some regressions, most importantly sam) from Unfuse bias add before pointwise ops by eellison · Pull Request #106912 · pytorch/pytorch · GitHub, also some other unexplained changes like convnext_base and jx_next_base in this same commit range (which sort of makes sense, @eellison landed a bunch of perf related changes)
Blueberries offsite was this week! The blueberries workstream is focused on accelerating SOTA transformer models using PT2, quantization, sparsity and other techniques. Some highlights: MFU is coming to the benchmark suite, some direct improvements to important models, int8 dynamic quantization with tensor subclasses. Many of these are not published yet, keep your eyes peeled at PTC!
PyTorch conference registration filling up fast. If you want to go and haven’t registered yet, you should register at PyTorch Conference | LF Events
Composability sync
Aug 24 https://www.youtube.com/watch?v=H6EUSsvDmbw - we spent time going over recent KJT progress (to be reduxed below), and Voz reported progress on tracing FSDP with hooks (also to be reduxed below)
Aug 31 - not livestreamed publicly, I wasn’t there, but apparently there was some discussion about streams for tracing FSDP (no minutes alas)
Distributed and PT2
Tracing FSDP with Voz is deep in the weeds on backwards hooks support. We are attempting to implement hooks in a way that doesn’t require consolidated forward-backwards. The general strategy is (1) have Dynamo emit graphs that have register_hook calls on intermediates (register_hook calls on inputs must not go in the graph, they have to happen as part of residuals), (2) write these register_hook calls in such a way that when AOTAutograd runs, the actual hook code (which is arbitrary Python code and is not safe to run in tracing) is not run, but instead we run a meta function (which performs any needed metadata mutation) and then insert a call function to the original Python function (which will show up in backwards), (3) have compiled backwards take care of compiling this call function in the end.
Per parameter FSDP is looking pretty legit. Andrew Gu has been looking at the performance of per-parameter sharding (where parameters managed by FSDP aren’t shoved into a single flat buffer) and has found that we only really pay a penalty of 5% with per-parameter sharding but get better memory usage. Meta only: https://fb.workplace.com/notes/618571790386318
This is not really PT2 related, but there’s an interesting set of posts about the future of Sympy circulating around: Towards a new SymPy: part 1 - Outline — blog documentation Funnily enough, the part of Sympy which Oscar calls out as “overused” (the symbolic expression system) is precisely the part we actually care about. Maybe a good reason for us to figure out some way to note use this part (me, personally, I want a compact representation and hash consing.)
I discussed this in a bit of detail in composability three weeks ago, but work on supporting fine-grained KJTs is going very well. This week, I worked with Michael Suo to get APS sparse arch tracing all the way through. I managed to get it going all the way through (though it failed on some seemingly unrelated problem.) So fine-grained tracing definitely seems like it will work, even if we generate tons of crappy guards. My plan for next week is to make a serious attempt at tracing multi-node model parallel sharded torchrec_dlrm.
This week, when I had spare time in the offsites, I worked on fixing a few one-off bugs. There were several that were pretty easy to nail:
Peter Bell is very close to landing inductor IR support for scan https://github.com/pytorch/pytorch/pull/106581 which allows for native cumsum/cumprod support. Now all we need is for someone to add a higher order op that feeds into this and we will have torch.scan!
Someone should add a “realize” operator to PT2, which would force materializing a tensor rather than allowing fusions across it. Christian Puhrsch would find this useful for ensuring epilogue fusion occurs on int8 mm (today, regular fusion causes the pointwise operation to get fused into a later reduction, instead of fusing the pointwise into the matmul)
ABI compatibility for AOT Inductor is continuing to proceed apace slowly, but one agreement is that we’re probably going to also only have the ABI compatible codegen for OSS as well.
In the PT2 weekly meeting, we discussed H100 benchmarking. There are a lot of interlocking parts to this: we need to upgrade Triton to get their H100 improvements, and not everyone on the PyTorch team has access to an H100. Still looking for someone to sign up for this.
CUDA graph updates are a thing now: CUDA C++ Programming Guide — CUDA C++ Programming Guide There may be some opportunities here. Elias says: “It mostly helps with eliding input copies. For the most part, removing input copies only really matters when you torch.compile only part of your model and leave the rest of the model in eager. This use case is pretty unlikely to train well anyway since you’ll still need to bifurcate the memory pool.” However, personally, I also think CUDA graph updates could be pretty useful for allowing you to deallocate the pool of memory needed by a CUDA graph, only reallocating it when it’s time to run the CUDA graph again.
Some big refactors that are in progress: refactoring skipfiles / allowed functions (talk to Yanbo), refactoring guard trees (talk to Animesh)
A bunch of new contributors being onboarded to Dynamo: Quansight is working more on Dynamo issues, and Jack Cao from PyTorch XLA is looking to help us with consolidated forwards-backwards-optimizer support in Dynamo as it is essential for XLA Dynamo perf.
KJT tracing updates: Tracing torchrec_dlrm with distributed sharding manages to get to the wait on the sharded embedding table lookups, at which point we are stuck on a complicated custom autograd function. Voz to take a look after finishing up intermediate backward hooks. In other news, the production folks on the workstream have finished getting rid of layer splitting for disables only, so they’re now quite interested in compiling through as well. Lots of foundational work that still needs to be done; hoping for Q4 but is very aggressive! Meta only: https://docs.google.com/document/d/1VTGEh0MqadAsuRy0s5u39wQhNwMSVgCgYewivMcBbuU/edit#heading=h.jknt1mqmztph
Animesh is going to be working on improving guard evaluation overhead, but there is still some disagreement among Voz, Jason and Edward about two major things: (1) should we port guards to C++ and do the rest of the scheme all in one go, and (2) should we stay in the “one compiled function, one check function” regime, or go straight to Voz’s one shared check function for everything.
Some folks from the Cinder team came to the PT2 weekly to talk about some challenges of running PyTorch with lazy imports. One big problem is the way Dynamo implements skipfiles by traversing modules to find all identifiers attached to them; this plays poorly with lazy imports. Other trouble points include decorators which put identifiers into global state, and our dispatcher registration mechanism.
Horace is complaining about compile time still kinda slow while he’s been working on llama. Profiling shows pytree is still big culprit (20%); we also spend a lot of time doing map_aggregate in FX (10%). Some discussion about reviving our fake tensor propagation rules caching idea.
Chien-Chin told us about the new PT2 DDP plans. We cannot directly trace DDP because it is implemented in C++, and we cannot easily port it to Python because the implementation is complicated by bucketing. So the idea is to implement a Python non-bucketed DDP, and rely on compile to optimize it away.
Horace told us about developments in LLMs. One thing he wants is dequant primitives in PT2: a way to take int3/int4 packed values and unpack them into a larger tensor, with the idea that PT2 would compile away the memory traffic. In general he doesn’t think we should directly do this in PT, as there are so many quantization formats.
Dynamic shapes
Last week I mentioned opcheck testing is usable, but Richard Zou is still evolving it on user feedback. A recent new change is to put the xfails into a JSON file so it can easily be automatically updated. However, there are still complaints from folks that it’s too hard to understand what goes wrong when a test crashes. Richard is going to investigate a two stage process now, where by we separate generation of test inputs and actually running the tests. To ensure generation of test inputs is kept up to date, we only need a single new test which runs all of the tests in the test file in one go and xrefs what tests are exercised with what we have recorded.
Horace wants a version of Tensor where some of the sizes are stored on device. This would allow you to perform a data-dependent operation without synchronizing; and you would still save on memory traffic because you would have kernels mask out memory loads when they go out of bounds of the dynamic shape. In some sense, this is a specialization of jagged tensor where everything in the jagged dimension has the same size.
Yanbo has been making good progress on understanding the state of our skipfiles/allowlist situation. Here is my attempt to record what he described to me in our 1:1.
First, what do these things do? For any given frame, we can make one of three decisions on it: inline - the default decision; skip - we never start Dynamo on this frame, and we induce a graph break instead of inlining into it (BUT, skipped functions may have overrides in Dynamo that allow us to avoid a graph break); allow in graph - we don’t inline into the function, but instead directly put it into the graph (and run it to do fake tensor propagation.) Skipfiles and allowlist control whether or not we do something different from the default decision.
Yanbo’s theory is that allowlist should be explicitly enumerated function-by-function. This makes sense; there’s a fixed set of operations we can actually put in the graph (coinciding with Torch IR; see composability sync), and they have to be audited to ensure they don’t do naughty stuff like mutate Python state.
Suppose that we didn’t care about compile time / Dynamo bugs at all. In theory, it shouldn’t be necessary to have a skip list at all, because you’d expect Dynamo to independently work out that something couldn’t be compiled and graph break. There is a big nuance here though: the torch module is skipped! Most of the time, this skip is bypassed for other reasons, e.g., a torch function is allowed in graph, or a submodule is explicitly allowed for inlining. But by default we won’t actually compile anything in torch (and this can be quite surprising for PyTorch devs!)
Chesterton’s fence rules everything around me. Sometimes we have manual implementations of functions (like nn.Module.parameters) which are unnecessary, because they were added back when Dynamo’s Python language support was not so good, but now we can just inline into these functions, but some seemingly benign skip rules are load bearing and cause problems. So many of Yanbo’s initial refactors will be oriented around preserving semantics as much as possible, while improving code organization.
Jason, Edward, Animesh and Voz got together to discuss some design questions about guard trees raised last week. The conclusion was that we are NOT going to do combined guard tries, Animesh’s plan as original scoped as is. One interesting thing I learned from this discussion was that guards with source-based guard structure deal poorly with guards that mention two sources, but Jason proposed a way to deal with this case: instead of directly having a guard like x.size(0) == x.size(1), instead have assignment statements like let s0 = x.size(0) and let s1 = x.size(1), and then have an extra guard that only makes reference to this local scratch space s0 == s1. These extra guards get run immediately once you notice that all of its free variables have been assigned. Jason’s argument is that size guards can be very fast to run if we compile them, so it doesn’t matter if they get run unnecessarily early. Some very rough meeting notes: Guard Refactor Discussion - Google Docs
PSA: when you print Dynamo logs, they come with a [0/0] marker that says what frame you are compiling, and which recompile of that frame you are on. [19/0] means you are compiling the 19th interesting frame for the first time, while [1/20] means you are recompiling the 1st frame for the 20th time (probably bad!) Occasionally, you will see [0/0_1]; this means that we restarted analysis on 0/0 for some reason, so this is the second (1 is zero-indexed) time around compiling it.
I mentioned to jansel that there are a number of dynamo refactors I’d kind of like to firm up: mutable variable trackers, a more accurate python object model, variable tracker cleanup (we have a big VariableTracker subclass hierarchy), more metacircularity (so that constant folding is a lot easier to implement.) Hopefully we can hit some of these during the offsite.
Composability
We had a very spicy session at composability sync this week on Torch IR https://youtu.be/FSPNXppkcjgComposability meeting notes - Google Docs https://docs.google.com/document/d/17O1R57oOZp_fK4dRf83UiM4fH6h6nblxjizTrbHP8BY/edit The crux of the matter is what to do about “Torch IR”, which is conceptually a PyTorch program capture representation that is produced by fx.symbolic_trace: an unnormalized format that contains precisely torch API operations that are part of PyTorch’s public API. It is a coherent concept that is used by folks today, but its denormalization makes it difficult to write sound analyses/passes on. Some argued that because it’s so difficult to use, we shouldn’t expose it, while others argued that the horse escaped from the barn. We were able to agree in the meeting what Torch IR is and what guarantees you should expect from it, but it’s still an ongoing discussion how this should relate to export.
Zachary DeVito’s been working on single controller distributed paradigm for PyTorch, where we issue commands of entire Dynamo traced graphs for external nodes to run. This is being done via a tensor subclass, but it is a bit unusual in that it doesn’t match other tensor subclass applications, where we don’t actually want to trace into the subclass itself, we just want to trace tensor operations on it “as if it were a normal tensor.”
Apparently optree https://github.com/metaopt/optree is slowly making progress into becoming an optional dependency for PyTorch: if it is installed, PyTorch pytree APIs will transparently make use of it instead, for hefty speedups. Pytrees are a big performance cost for PT2 compile time, so it will be nice for this to land; so nice that Richard Zou has been wondering if we shouldn’t actually just make this a required dependency.
Discussions on internal reliability continue. It’s going to be some sort of multi pronged approach where we negotiate with PGs what testing we absolutely must do, while at the same time improving testing on poorly exercised parts of PT2 (e.g., PT2+FSDP) and working out periodic tests that are covered similarly to how we cover benchmark results in OSS.
Dynamic shapes
PSA: We’ve covered this before, but someone asked me about this so I’ll repeat it: our plan for PT2 support for table-batched embeddings is that we will eventually support capturing embeddings both with and without the fusion preapplied (e.g., by module swapping). It’s your choice then whether or not to reuse preexisting optimization passes, or write a new PT2 based optimization .
PSA: When registering C++ implementations (meta or composite) that take SymInt, make sure to pass SymInt by value and not by const reference. This applies to composite types like optional<SymInt> too. Unfortunately, we don’t check this properly right now: https://github.com/pytorch/pytorch/pull/109727 is wending its way in but I have to fix all the people who did it wrong first lol.
There’s still a lot more to do. There’s a lot of use of size hints in inductor which need to be rewritten to deal with the unbacked case when no hint is available. Another unusual thing about Adnan’s setup is he is using AOTInductor, so we’re also getting a lot of extra asserts from add_runtime_assertions_for_constraints_pass.py which also don’t compile atm.
Jeffrey Wan has worked out that we should represent singleton symints (to be used to represent ragged dimensions) as sympy Atoms, which compare only equal to themselves. This is better than Symbol because they don’t show up as free symbols this way.
Compiler/distributed offsite was last week! PyTorch Conference talk slides are due to Linux Foundation end of this week!
Dynamo
Our initial take on mutable variable trackers was “well, it is probably technically feasible, but it’d be a lot of work and the ROI is not obviously there.” It came up again this week, though,for perf reasons: RFC / Discussion - Mutable Variable Trackers - Google Docs from Voz
We discussed accurate python object model: definitely something we should do for user defined objects, maybe Fidget-Spinner will work on it. We have some Dynamo bugs recently relating to classes with nontrivial metaclasses (like abc) and multiple inheritance.
We have a proposal for guarding on Dynamo configuration, which should make it a lot easier to tweak config options: Dynamo guard on global configuration · Issue #110682 · pytorch/pytorch · GitHub One notable choice we make is that outer-most torch.compile config wins; if this would be annoying for you please comment on the issue.
Tracing FSDP
We talked about the relative importance of landing tracing FSDP quickly during the offsite. The general consensus was that, while this is an important capability, the more time pressing problems are optimizing tensor parallel compute (as it’s harder to manually get optimal overlapping in this regime) and tracing DDP (which Chien-Chin is working on.)
During the offsite, we came up with a full plan for Dynamo-level support for propagating hooks to backwards. The primary complication is that, in full generality, a backward hook installed in a Dynamo compiled region may be arbitrary Python code that would vary from run to run, but we emphatically do not want to guard on it (nor can we, since we didn’t inline into the function.) In the simple case, the function is constant from iteration to iteration and we can bake it into the backwards graph (this is what is currently implemented); in the complicated case, Dynamo must construct the residual function, and then somehow pass it to AOTAutograd compiled function, so AOTAutograd knows to know that particular function is what should be invoked when backward rolls around. This can be done but it’s all quite fiddly. For FSDP we don’t need it in full generality because it’s a constant function.
More folks are collaborating on Voz’s experimental FSDP tracing branch: https://github.com/pytorch/pytorch/tree/voz/fsdp_autograd3 To run things on the branch just say torchrun --standalone --nproc_per_node=2 fsdp.py (will run with compiled forwards, but NOT compiled backwards). Current status is that compiled forwards works, compiled backwards does not. The problem is that compiled autograd has to do a pre-pass with fake tensors to construct the FX graph, but during this pre-pass it is unable to run hooks, and that means parameters aren’t the sizes it is expecting.
Not quite FSDP, but putting it here: on the subject of single controller, Haiping Zhao also looking at it this problem space, much more from the distributed side. He, Zach and Horace have been chatting.
uint2/uint3/uint4 support in core to be prototyped as Python subclass by torchrec folks (lead by Ivan Kobzarev)
Decent chance we are going to get dequantize operators that can show up in export IR
We will have a pattern matcher that will let you compile regular Python calls in PyTorch IR into appropriate ATen matchers, mirroring how Inductor’s pattern match infra works. This will support just returning fx.Nodes to you so you can do arbitrary transformations, instead of just doing a replacement.
Richard Zou has been trying to convince people to use the new operator registration API, but he has been noticing that people really like the old fashioned autograd.Function API, because it doesn’t require them to do work for things they don’t care about (e.g., supporting other transforms). Since we need to support this anyway, we are going to make sure Dynamo’s support in this regime is good.
AOTInductor is currently working hard on GPU model support, but some folks have been poking at it for CPU, overhead sensitive workflows. There will likely be some work done in this area, cool increase in scope.
Export input/output matching is being a problem again. This is the AssertionError: traced result #1 (<class 'torch.Tensor'>) is not among graph-captured output. Someone should rewrite this code.
Dynamic shapes
ysiraichi is transitioning to PyTorch XLA, so he will have less time to work on dynamic shapes specifically.
Not sure what’s going on with blueberries readout lol.
Compile time does seem to have gotten worse. @Chillee has been complaining about compile time, although a lot of it is in Dynamo tracing. It is hard to see the effect of Dynamo in our current benchmark suite because it is heavily Inductor biased. Some improvement from guard hashing, but Horace says it’s only 1-2 seconds.
Sorry about the month’s delay! Between more vacation and PTC there wasn’t much time to do a writeup over the weekend.
Executive summary
Big tickets
PyTorch Conference happened! Thanks everyone who attended, there were lots of fun discussions. You can watch the talks at https://www.youtube.com/watch?v=dR0lHxt3Tjo&list=PL_lsbAsL_o2BivkGLiDfHY9VqWlaNoZ2O . Some fun in person discussions that I had: (1) with Pierre Guilmin, you can now torch.compile complex tensors: Add complex tensor with subclassing by pierreguilmin · Pull Request #48 · albanD/subclass_zoo · GitHub This is actually going to be the preferred way to torch.compile complex numbers as you Triton doesn’t support interleaved layout and you’re not going to get efficient matrix multiply that way anyway (because the built-in instructions don’t support complex.) (2) Ho Young Jhoo and Nuno Lopes had some interesting work on automatically pipelining NNs, it was quite interesting. (3) Jack Cao and I sketched out what single step graph should look like in Dynamo, track progress at https://github.com/pytorch/pytorch/pull/112296
PyTorch 2.2 release is coming! The branch cut will be Dec 1.
Dynamo
We’ve been having lots of discussions about what it will take to get Dynamo to the same level of stability as long running compiler projects like HHVM or LLVM. Some thoughts about refactoring pieces at Refactoring Dynamo for stability - Google Docs As a smaller step, @voz has organized a weekly triage meeting for PT2 issues, separate from the regular PT2 weekly.
@suo is taking a serious look at getting torchbind to work on PT2. Some basic design notes at PT2 torchbind - Google Docs ; we also discussed this at composability sync
In the land of tracing FSDP, there is currently some grunging about in PyTorch’s accumulate grad implementation. It is fairly complicated, including logic that checks the reference count to decide whether or not to reuse a buffer inplace or not. There is some debate about whether or not there should be an accumulate grad aten op (@jansel implemented one that lowers all the way to inductor), or it should be traced through by Dynamo.
Ying Liu has been working on a tensor subclass for async execution. We discussed it in composability sync. The idea is that you can trigger an operation (typically communication) on a side stream, as well as some follow on operations, without having to literally move the follow on operations to the point where a sync happens. This also means that code in torchrec that has to be manually written as a pair of custom autograd functions for req/wait can be written in an intuitive, autograd style. We have a version that does this manually with callbacks (only queue kernels onto the stream at some known later point in time) and Ying is working on another version that uses streams only. One interesting thing we noticed that when you schedule allreduce in forwards first, backwards will naturally schedule it last, but you actually want the allreduce to happen ASAP! @albanD suggested we may be able to add an API to modify the priority order of autograd backwards, could be useful.
repeat_interleave dynamic shapes support was reverted due to S376879, this revert may itself have caused a sev S377088. It turns out that this diff was not related to the SEV, so we are relanding it.
If you need to force an input integer to be dynamic using mark_dynamic, one way to hack it is to pass a 0xN tensor instead of an int and then project out the int again with size(1).
Vibes: I’ve been back from recharge for only a week, and already it feels like an avalanche of bugs! Phew, lots to burn down. I asked Twitter for some time tracking advice: https://twitter.com/ezyang/status/1745523916624330974
Jack Cao has a design doc for Dynamo single step graph capture [RFC] Dynamo Single Step Graph · Issue #117394 · pytorch/pytorch · GitHub and we ratified it at composability sync. The way it uses compiled autograd to generate another Python program to inline into from Dynamo symbolic evaluate is pretty cool, check it out.
Did you know that mypy in daemon mode is way faster at type checking than lintrunner?
Landed stuff:
Stop unconditionally applying hermetic mode - hermetic mode prevented you from doing things like calling torch.compile or returning tensor subclasses from operator implementations registered to dispatcher. I’ve decided multipy is dead and so we can relax this restriction.
Add AT_DISPATCH_V2 - this cool new macro lets you dispatch to multiple dtypes but without having to count how many extra dtypes you add. Check it out at Dispatch_v2.h
I did some live streamed bug fix sessions, which you can watch on Youtube. Check it out!
We had an internal SEV review. One thing that stood out to me was that two of the SEVs were compilation slowness stemming from dynamic shapes accidentally being turned on when it shouldn’t be. Dynamic shapes trouble.
Jack Cao and I got a design for dealing with saved for backwards intermediates, which is that we’re going to generate a pre-dispatch ATen FX graph into Dynamo, rather than directly represent torch.*. We’re pretty sure this should work. Track Jack’s progress at https://github.com/pytorch/pytorch/pull/112296
Richard Zou and co have been working on making the Dynamo CI tests less flaky. They’ve made a lot of progress. Right now, all of the tests in CI are reasonably hermetic (they reset before running) and they’ve clustered the failures. A lot of very simple stuff (e.g., error where Dynamo uses a variable that’s not defined) and then a huge long tail of niche failures. Not many accuracy failures. One big problem is many problems only repro in CI environment and not locally.
A number of new folks from PL&R are ramping up on Dynamo! The extra manpower is much appreciated.
Yanbo Liang is thinking about how to measure compile time in our prod workloads. The challenge is full E2E tests are quite difficult to run. But maybe simple components like Shampoo can be extracted out and tested on their own!
Simon Fan is working on improving testing of compiled autograd by turning it on our torchbench suite. Meta only status: https://docs.google.com/spreadsheets/d/17aCEcAcif-1saHrdqALjfr-ybRMl_uEq7mqje5whPZw/edit?usp=sharing the summary is some pass, some fail. _cudnn_rnn_backward needs meta support, and there are some side/stride mismatch issues. Fire up the minifier! He’s also running torchbench with DDP.
New einops style library einx from the community: Reddit - The heart of the internet Seems pretty neat! This is my continued reminder that first class dimensions are also a thing in PyTorch too.
Joel, Jeffrey, Alban, Brian and Edward convened to discuss subclass view fakeification again. Subclass view fakeification occurs when we are given a tensor subclass which is a view of another tensor (the canonical example is a nested tensor which is a view of a dense tensor of all the packed data), and we need to convert it into a faithful fake representation so we can simulate operations on it in Dynamo and AOT Autograd. Construction of views in fake tensors is traditionally done by fakeifying the base tensor, and then reapplying a recorded view function which specifies how to “replay” the view on an arbitrary new base. The problem of subclass view fakeification is that these view functions typically hard code size / tensors that are free variables of the view operation, but when fakeifying, these need to be swapped out with symbolic integers and corresponding fake tensors. Joel’s resolution after the meeting was to reify view functions so that this information can be swapped. Notes: Subclass View Fake-ification in PT2 - Google Docs
Shampoo compile time is still a problem. I talked to some folks on Wednesday who were like “our job is stuck in produce_guards” and it turned out to be the exact same tensors_definitely_do_not_overlap guard explosion that caused two other SEVs described at Meta issue: Automatic dynamic shapes can cause compile-time performance cliffs · Issue #118213 · pytorch/pytorch · GitHub. Brian is going to try to fix the tensors_definitely_do_not_overlap problem in a few weeks. I showed Yanbo how to navigate the logs to find the culprit (in this case, just searching for symbolic_shapes logs was enough to identify this as the same problem.) There is some difficulty reliably turning of automatic dynamic shapes (which would help with this problem) that needs to be studied in more detail.
A bit of chatter about what to do about backtraces in distributed interleaving each other. Chip Turner shared that if you pass appropriate arguments to torchrun like torchrun --role mnist-trainer --log-dir /tmp/l -t 3 -r 3 mnist/main.py good things happen. Unfortunately in internal prod we are still shoving everything to stderr but maybe we can change that. Meta only: https://fb.workplace.com/groups/mast.users/posts/1451868658730526
We’re using dmypy instead of mypy for typechecking now in lintrunner. Typechecking is a lot faster! If you think there’s some weird cache problem, you can say dmypy stop to restart the daemon.
Alban working on a concept of “accelerator” for the PyTorch library, to better support non-standard backends. Some pain points including pinned memory (which is currently CUDA specific) and how to write library code like FSDP in a way that can handle multiple devices. Doc at https://docs.google.com/document/d/1TySu95kPLc6kNzlOg1T8IRGHVkezv8cWyweEXYZaxlU/edit#heading=h.x2rqjkjdhxak and we discussed it at composability meeting.
Jeffrey Wan has been working on https://github.com/pytorch/pytorch/pull/117904 . Most notably, singleton SymInts are becoming a nested tensor specific concept, getting tensor stored directly on themselves, and are being supported being passed directly to a tensor constructor, so you can create a nested tensor directly from torch.empty so long as you appropriately pass in a nested int. The motivating reason for all of this work is so that we can reuse all autograd formulas with nested tensors; this is what necessitated making sizes well defined for nested tensor, despite the existence of a jagged dimension.
Brian: Has been working on a lot of internal driven fixes for DTensor and PT2. One particularly notable PR is a new API proposal AOTDispatch: allow subclasses to correct when we guess metadata of tangents incorrectly by bdhirsh · Pull Request #118670 · pytorch/pytorch · GitHub for working around problems where the forward/backward have different tensor metadata when a subclass is involved. In the long term, Brian will likely take on fixing it properly (by having AOTAutograd recompiling when outputs show up and they mismatch what the existing compiled graph needs.) The difficulty here is mostly because partitioning decision has already been made at this point.
Composability sync https://www.youtube.com/watch?v=kSOmyARCbyM (minutes Composability meeting notes - Google Docs) had a discussion about how exactly to handle AsyncCollectiveTensor in PT2. Broadly, our conclusion was to go the simple route: we wait on all input AsyncCollectiveTensors, output tensors from collectives don’t wait and instead produce AsyncCollectiveTensor from Inductor. Some debase about how some applications like FSDP do need fine grained stream control to control memory usage.
Michael Suo asked me, what are non urgent high impact things I (or others) can do? The big one that came to mind was improving the typing in PyTorch codebase. Typing serves as documentation and helps catch errors. It is a virtuous circle: the better typed we are, the more likely new code is to be typed.
Will Feng has picked up FSDP patch set from Voz. Most recent branch does not work end to end: the gradients are always zero. My advice to Will was to work on landing the individual fixes to main and trust that Voz has identified all the missing gaps. In the leads meeting there was some discussion about what to do about this workstream overall after Voz’s departure; jansel still supports this strategically and we are still committed to it.
Richard was delighted to tell me that all flaky tests in Dynamo are fixed: keep an eye out for an official announcement.
Did you know that PyTorch actually has two sources of truth? Many internal oriented developers develop on top of fbcode to ensure fast lands into fbcode. This can result in desynchronization of fbcode and GitHub and it is necessary to reorder commits. But commits are not necessarily commutative; when they are not, this results in a “splitrace” (https://docs.google.com/document/d/1LJFKwD_lBudEt4kiUIMh_LkYp0_CFVaUSe64kIPglwo/edit#heading=h.j49wad13wr3z). I chatted with Ivan Zaitsev in case I had some good ideas for how to deal with it. One thing is that potential conflicts between diffs is unavoidable because we are not doing a bors-style landbot. So the name of the game is identifying if commits are likely to be safe to reorder. We have some evidence of commutativity from PRs themselves, as their final test is typically N commits behind their actual merge commit. In a decentralized system, it is best to first ask if you can make it centralized first: much simpler!
Elina Lobanova joining us to help with some observability logging stuff. She told me some good ideas: one that stuck out to me is how we should do feature flagging: we should read them out at training process start and then keep them the same until the job relaunches (Google flag style). This way, you can diff flags between jobs and see if they changed.
I popped into the Inductor weekly sync to get some info about topics. I pitched us rewriting our test suite to have one file per test and more standardization; there was lukewarm reception for this (although one person from the HHVM team was like “yeah, we have 15k test files in HHVM, what’s the problem?”) No one apparently helping anyone with problems internally due to inductor. Unbacked symints enablement workstreams are unblocked. Inductor workstream tracking at https://docs.google.com/spreadsheets/d/1pwW5bRZqIzbi1026JrKo83P1P2Vbf8MG8CF09-48O9Q/edit#gid=0
Ryan Tremblay reported a worse loss curve when torch.compile’ing a transformers model. This was very difficult to debug, but @bdhirsh eventually pinned it down to a stride mismatch problem in the meta implementation of flash_att_bw: https://github.com/pytorch/pytorch/pull/119500 Great sleuthing! This can potentially affect all transformer models training with torch.compile, so if you are seeing bad loss please try out the one line fix.
Simon Fan published a very nice update on compiled autograd. The post is meta only: https://fb.workplace.com/groups/1096365031404923/posts/1099790361062390/ but the summary: (1) compiled autograd is now being run on all PT2 benchmark runs on dashboard, (2) some backward ops are missing meta implementations that we need to add e.g., aten._cudnn_rnn_backward, aten._embedding_bag_dense_backward, (3) nicely, the speedup 3-11%, now that a refcounting problem in accumulate grad is resolved, (4) less nicely, peak memory usage is up, compile times doubled and CUDA graphs often does not work. On the subject of compiled autograd and DDP, Chien-Chin reports that nanogpt works, passes accuracy and (surprisingly!) performs better even though there is no bucketing yet. However, there’s a bug with zero_grad where it forces Dynamo to recompile every iteration. Meta only: https://fb.workplace.com/groups/1096365031404923/posts/1099785997729493/
From Yifu Wang, there’s a new, “native” implementation of functional collectives in Inductor IR and it’s getting close to the point where the old funcols (which are manually implemented with one IR node per collective) can be switched to them. Meta only: https://fb.workplace.com/groups/1096365031404923/posts/1100109071030519/
Two big happenings on the nested tensor front. First, we have agreed to stop using the term “nested tensor” as it is ambiguous, and instead use NJT (nested tensor with jagged layout) and NST (nested tensor with strided layout) to disambiguate between the two layout formats. Most development is happening on NJT. We devoted the first half of this week’s composability sync to working on nested ints; the final outcome was that (1) nested ints do NOT have device, (2) they test value equality on CPU tensor, and (3) they optionally can cache a CUDA tensor to avoid repeatedly resending it to device. Jeffrey Wan to follow up on this.
NVIDIA TensorRT team is going to extend torch._dynamo.mark_dynamic to support also specifying min/max constraints.
We historically focus a lot on CUDA performance. Nikita Shulga has been looking into performance of our LLM models against other implementations on CPU. GitHub - malfet/llm_experiments One thing he noticed is that our lower precision matmul implementation on ARM is really bad because we didn’t vectorize it. What should you do if you want to use PyTorch but in a deployment environment where you need no dependencies and low binary size? Probably something like Executorch runtime with a thin frontend pasted on top for dealing with KV cache / beam search / stuff that’s hard to export, and then AOTInductor exported blocks that you are pasting together.
PT-D has been on people’s minds. At high level, one of the things folks are most concerned about is composability: distributed involves a lot of complex features, all of which need to work together. I’m not too worried at a fundamental technology level, because many of the things we want to support are orthogonal and independently make sense, but ensuring we have adequate testing of all the combos is something that has persistently plagued our project even in simpler cases.
Some investigating from Richard Zou about how to productionize torchdim. Here, productionize means eliminating the monkey patching it is currently doing to add support for Dim to functions like torch.sum. One potential approach is to make torch function to support non-Tensor arguments having overrides, ala torch_function objects passed as non-Tensor args should trigger overrides . Another potential is just to directly incorporate the modified logic from torchdim into our C binding code. Both of these are nontrivial work.
Executorch is starting to look at how to handle custom ops, e.g., those in torchvision. Mengwei’s initial thinking is to get people to write their custom ops in ET compatible style, and then adapt them to regular PyTorch dispatcher. Improving ExecuTorch Custom Ops - Google Docs
There’s been some agreement to unify on NJT, but Colin pointed out that there is not a completely solid commitment from torchrec side to actually move everything in torchrec to NJT, so there is still some ambiguity here.
Moto Hira has switched teams, so torchaudio is now ramping Ahmad to own the library
Some stuff I found out from 1:1s:
Oguz Oulgen: his team is ramping by fixing bugs in Dynamo, but they’re going to be moving to bigger things soon. The two big themes they’ll be tackling are Dynamo reliability and Dynamo compile time. Oguz is still trying to define what exactly the objectives under these themes will be.
Horace He is working on selective activation checkpointing. Meta only: https://docs.google.com/document/d/1kNVs5vKkL-CNa2Ufvqex6VgwF8kAqF9aS6ca9pBuB_8/edit but the idea is there will be a level 1 API where you explicitly specify what you want to checkpoint, and a level 2 API where you want to hit some memory budget within the region you’re checkpointing. The level 2 API is difficult to implement without a full graph, so it will likely not be supported in eager mode OR you can compile it, get the list of checkpointing decisions, and then you can feed that into eager mode. This work is based off of a cool prototype fmassa made. Horace hoping this doesn’t take too long, and also still planning to work on single controller, oriented at (1) fine tuning use case and (2) really big cluster use case.
Animesh Jain: should be able to wrap up C++ guards in the next few weeks, next on list is helping with subclass/Dynamo related interactions
Brian Hirsh: looked into how to do the non-overlapping test more efficiently (without doing quadratic pairwise checks) but this is actually kind of cursed. The problem is that if you imagine a 2D parameter buffer, the individual inner parameters correspond to non-overlapping tiles, which means that any single tile is NOT contiguous. Need some sort of multidimensional tiling algorithm. Has been working hard on DTensor / PT2 integration, lots of bugs! But it’s very real.
Avik C: had a chance to brief him on how symbolic shapes works. Looking forward to more collaboration between the eager mode online solver, and export’s offline solver.
Nikita Shulga: improving LLM model perf on CPU. Llama on ARM in fp16 in PyTorch is less than 1 tok/s (compared to 15 tok/s on llama2.cpp). Also looking into gguf compatibility, quantization subclasses, and checking if it works with AOTInductor.
Adnan Akhundov has knocking around supporting cond directly in Inductor, for host side, runtime control flow. WIP.
Composability sync - we sat down and worked out the accumulate grad problem, which is blocking compiled autograd x DDP. The new plan is to decompose accumulate grad before it gets to Inductor. Animesh to look at it. Check out Composability meeting notes - Google Docs for notes
Non-strict export is a thing! Non-strict export is an alternate implementation of torch.export.export which uses make_fx tracing rather than Dynamo tracing. If you are suffering from missing Dynamo support, non-strict can help; but it’s not all beneficial, because make_fx is unable to handle some patterns that Dynamo can handle transparently (e.g., x[s0:s1] forces specialization on s0 and s1; torch.tensor does not work). A lot of people are using it now.
Someone asked in leads meeting if tensor subclasses are “public” API surface. Well, they are… but you kind of have to be a PyTorch expert to use it. So we don’t necessarily expect them to be self service.
I’ve been working on improving logging inside Meta, with some implications for OSS too. In Meta, I’m trying to get us to stop muxing all our ranks together and write them to separate files https://docs.google.com/document/d/1tf_gJ3KlKFqjsTa39yVNymDSu57Lv3mHiWi9dzJJOUk/edit (this requires some new API support in torchrun). I’ve also been working on a logparser called tlparse GitHub - meta-pytorch/tlparse: TORCH_LOGS parser for PT2 . I want to do a lot of things with it, but right now what it does is it looks at all the compilations that happened and gives you a nice overview of where they are, by rendering all their call stacks into a trie. Still rapidly evolving. It’s pretty fast too: 500MB/s, which is not the fastest but means a few GB logs is no big deal.
We got some clarity on how exactly to deal with the naive implementations on KJT embedding that torchrec uses by default. These are quite inefficient, and we do not actually need to trace them as post-export we will be unflattening modules and doing module swaps. We’ve come to the agreement that it’s not necessary to directly trace these (which is very slow); instead, we will somehow trace some higher level thing (either by tracing table batched code, or putting in dummy functions for the things to be module swapped.) Internal xref: https://fb.workplace.com/groups/6829516587176185/posts/6880175418776968
Flavio has been working on fbgemm metas. These are annoying because the fused optimizers are all code generated in C++, so it’s most convenient to do the meta in C++. Good progress: https://github.com/pytorch/FBGEMM/pull/2347
Ivan has been working on tracing through torchrec async comms, rewriting them so they are in synchronous style without custom autograd function and therefore PT2 traceable. Interesting blocker: derivatives are missing on functional collectives; also some necessary primitives like reduce_scatter_v are missing
Colin is going to move into the dynamic shapes space per Adnan.
ghstack 0.9.0 is out. This release has a big new feature: you can now specify a subset of commits in your stack. Simply say ghstack submit HEAD~ to push only HEAD~ (but not HEAD). Commit ranges are also supported. There’s also a number QoL improvements: we now no longer include the PR title inside our generated head/base commits, we no longer strip @ from email addresses in commit messages, and there’s a smoother GitHub auth token flow. Most open issues in our bug tracker were fixed. There’s also an experimental --direct feature which lets you generate PRs that merge directly into main, but it’s not tested to work with pytorchbot, this is mostly useful if you’re using ghstack on your own repository. Internal xref: https://fb.workplace.com/groups/533197713799375/posts/1839730956479371/
Meta-only: I’m waiting on Kurman for an alternate implementation in torchrun that will help us conveniently avoid interleaving multiple ranks of logs together. ETA Monday.
Composability sync was pretty spicy: Jason Ansel reopened the question of whether or not we want to be supporting a pre-dispatch serialization IR at all. Composability meeting notes - Google Docs .
The composability minutes don’t have the full story: after the meeting, there was a bunch of back channeling with Horace and Jason, and we got back to “OK, I guess we need to support pre-dispatch IR”. One major thing that convinced Jason was that we don’t actually play on exporting FSDP-ized models (instead, the model will be unflattened post export and the FSDP applied at that point). For Horace, solving the org problem of needing to move your model around to different transforms and not at all in one go seemed insoluble without the export format. Horace to enumerate all the cases where we do side tables that you can’t export with pre dispatch: checkpointing and user defined Triton kernels.
On a side note, there was some late night discussion about what to do about subclasses and pre-dispatch export. My explanation to Michael Suo was that if a subclass can only be desugared after autograd, then your pre dispatch IR must include the subclass, and your target runtime must know how to deal with the subclass. In some sense, this is not surprising at all, because pre dispatch IR really hasn’t had any of PyTorch’s internal subsystems resolved ahead of time, so you are going to need, e.g., a full on autograd engine to actually run it (in practice, these export IRs are going to target PyTorch again). Sometimes, subclasses can be implemented before autograd, but you often give up quite a bit to do so. For example, for DTensor to be pre-autograd, would give up the capability to have a different sharding pattern between forwards and backwards; for NestedTensor to be pre-autograd, necessitates every operation nested tensor to have a separate ATen operator with its own derivative formula (as many nested tensor operations cannot be implemented just be desugaring). In some sense, this is not surprising: people are using __torch_dispatch__ because there are things you can’t do unless you’re below autograd!
Per-parameter FSDP is very serious business. With some upcoming training use cases that I cannot describe here in public, per-parameter FSDP is in serious contention for being the distribution mechanism. Will Feng has been focused on torch.compile’ing per-parameter FSDP (internal xref: https://fb.workplace.com/groups/1096365031404923/posts/1108181883556571/), and generating more AOTAutograd features that Brian has been helping consult with.
I had a chance to ask Brian what was going on with FP8 and DTensor composability. There is progress going on here (contrary to my impression), and it seems the current design problems revolve around cases where first DTensor then FP8 ordering wants to be violated. In particular, in some cases DTensor wants to do something special when a conversion to FP8 happens. The current thinking is that to_fp8 will be a dedicated ATen operator that DTensor can override, and we just need to figure out how to dispatch this to the FP8 subclass (similar to backend select, we have a dispatch problem since no argument to the operator actually takes in an FP8 tensor) before we finally get to proxy tensor (since we don’t want to_fp8 to show up in the final, desugared of subclasses graph.) Brian is consulting on this.
The state of NestedTensor has been on my mind.
Jeffrey Wan has a fairly major change to nested int out: https://github.com/pytorch/pytorch/pull/119976 The implementation in the PR is actually different than the design Christian advocated for in the meeting, where sequences are canonically CPU but can be cached on CUDA. The main problem with Christian’s design is if you are given only a CUDA lengths tensor, Christian’s design as is forces an immediate sync to establish the CPU source of truth. More discussion necessary.
Basil Hosmer’s old fold prototype was back in the news. The context is that I finally internalized something Michael Suo was telling me, which is that stock NJT cannot handle torchrec KJT, which requires two dimensions before jagged dim. How exactly should this be modeled with nested ints that Jeffrey is working on? If a nested int corresponds to a Seq dim in Basil’s formulation, fold tells us pretty directly how to model this: (feature, batch, jagged, embedding), where jagged is a Seq dim. It is a little unfortunate that the stride note was never written, but with only a single jagged dimension, intuitive multiplication of Seq with int does what you want. Not sure if anyone else is on board with this, need to get more alignment. One thing fold doesn’t answer is how you should resolve degrees of freedom of if Seq’s data is stored on CPU or solely on CUDA. torchrec makes one particular choice, but there are others! Ivan tells me, however, that typically you don’t want to store stuff on CPU if you can avoid it.
Michael Suo has been pushing us to think more about the long term state of NJT and torchrec. This is not in the plans right now, but in the long term, we would ideally have NJT be the backend representation for JT and KJT. But torchrec has pretty stringent eager performance considerations, so it is not at all clear how you are ever going to actually manage this. This is somewhat reminiscent of the situation with complex tensors, where we have a C++ implementation, but for PT2 a Python implementation would be much preferable (but we can’t get rid of the C++ implementation because eager perf would suffer.)
Oguz/Chip thinking about super big jobs. When you have so many nodes, when one node fails you’re going to have to restart. This is going to happen a lot. This means warm start matters a lot, and the model is not changing. We’ve already got a memcache thing going on for compiled Triton kernels: think bigger.
Richard has been thinking more about custom ops; he has a new custom op API proposal https://github.com/pytorch/pytorch/pull/120345/ . One of the tender design questions is “why do people want to put plain PyTorch operations in their custom operator, the so-called traceable operator”? Reference this old document for some use cases: PT2 black box escape hatch - Google Docs Another interesting idea that popped up: if someone puts a Triton kernel in their CUDA implementation of a custom op, how do we get this to Inductor in a way that it can understand and directly incorporate the Triton in, without generating an actual call to the custom op? One idea is for operators to have a more “structural” implementation, e.g., TritonKernel, FXKernel, where it’s not an opaque Python callable and you can poke at it from the compiler to get the important information. And you could automatically generate these by using Dynamo. Food for thought.
Torchbind fakeification is making progress by Yidi Wu at https://github.com/pytorch/pytorch/pull/120045 . There’s some API bikeshedding on what exactly the API for getting the fake version of a torchbind object and testing its guard should be.
James March was complaining to me that OSS C++ logging has no timestamps on NCCL logs like “watchdog timeout”. This probably is not hard to fix, someone should check it out.
Animesh Jain has been steadily working on C++ guards, it’s a big stack of PRs that is slowly landing. He is planning to move into the accumulate grad question, which we had discussed in composability last week. We worked out some more implementation details: fixing .grad handling in Dynamo is probably the tall pole in the tent, desugaring of accumulateGrad will happen in Dynamo via a polyfill, we will never handle the refcount == 1 case.
Mengwei Liu has a proposal for letting you load inline Executorch kernels into regular PyTorch Google Colab
https://github.com/pytorch/pytorch/pull/119868 multiple folks ran into this (manifesting as making a fake tensor when you already have a fake tensor), thanks Laith for working on the fix!