We are one week away from branch cut for PyTorch 2.0. We are continuing the slow grind of last mile bugs: there are still no major features we want to get in before the branch cut. We have reached the point where there are no more “easy” bugs; every bug is nontrivial and has someone working on it. On the people front: Brian is focusing on inference functionalization + AOTAutograd related OOMs; Voz has passed off trace time improvements to Edward.
Expression hoisting. Natalia from Inductor has been pitching in to help us with some dynamic shapes related Inductor problems. She landed symbolic shape hoisting to host compute dynamic tensor shapes for indexing on the host by ngimel · Pull Request #93872 · pytorch/pytorch · GitHub which greatly improved the quality of generated code, and hopefully also fixes a decent number of floor/ceil problems. She’s been working on unet upsampling, which uses floating point to do indexing computations (oof).
Tracking dynamic shapes performance.@gchanan has asked us to start tracking the performance of models running with dynamic shapes. This should be integrated into the performance dashboard; hopefully it can happen in the next month; but perhaps it should wait until we move performance onto GCP A100 in CI, as the current dashboard run takes 16 hours.
Dynamic shapes minifier. The dynamic shapes minifier is less broken now; Edward spent some time this week working on it to extract repros for LearningToPaint and Background_Matting accuracy errors. However, it still does not work very well (AOT accuracy minification is fundamentally broken and needs a rewrite.)
More on tracing speed. OpTree is still shambling along, but at this rate unlikely to make branch cut. Voz passed off his hacky prototype to Edward, who has implemented a sound version of the optimization at https://github.com/pytorch/pytorch/pull/94047 ; it isn’t as fast as the hacky prototype, but in exhaustive testing appears to match behavior exactly.
aot_eager inference: -6 (-3 WoW). The regression is due to the CUDA 11.7 upgrade, which introduced new accuracy failures. This upgrade also caused this exact set of models to start accuracy failing on training with static shapes, so it’s probably not dynamic shapes specifics, but by our metric design this still counts as a regression. We haven’t had a chance to investigate yet.
aot_eager training: 0 (+1 WoW). I believe the timeout was fixed by some of Voz’s performance improvements.
voz: landing dynamo graph breaks. bug fixes? post branch cut: forbid specialization (previously known as guard inversion), test bankruptcy
Our north star: Dynamic shapes at feature parity with static shapes (but NOT turned on by default.) We might want to adjust this so that dynamic shapes is “on” by default, but we assume all inputs are static by default.
It’s the eve of the branch cut for PyTorch 2.0. Training support is still not landed to master, though Horace says he’s made progress against some of the FSDP bugs plaguing his PR. Brian’s functionalization for inference is on the cusp of landing, after working through considerable flakiness in Inductor. The general mood is that we need more inductor developers. We had a lot of forward looking design discussion this week, check the bullets for details.
Tracing speed improved on master.https://github.com/pytorch/pytorch/pull/94047 has made it to master; on some models, it can cut dynamic shapes tracing time in half. There is some low hanging fruit for extending the approach here to more operators. In general, we’ve found improving trace time challenging as Python profiles tend not to identify problems directly (one thing we note is that we don’t get aggregation on a per-op basis because of all the metaprogramming we do; another hypothesis for our difficulty is the amount of Python-C++ crossings we tend to do). We don’t think Sympy is the main cause of slowdown, but Sympy can cause other problems when it gets into pathological cases (see below.) We need to start tracking this metric in our runs.
Dynamic shape induced graph breaks are way down. Voz and Joel have done a lot of good work hosing down extra graph breaks from dynamic shapes. The remaining holdout is avoiding graph breaks on negation; fixing the graph break is easy but the resulting graph appears to cause Inductor to infinite loop; Voz was unsuccessful at diagnosing the problem.
Dynamic by default. jansel has argued us back into goaling on dynamic by default. The general idea is that we should be leaning into PyTorch’s historic flexibility and support for dynamic shapes. Jason’s straw proposal is the first time we assume it’s static, and upon recompile we compile with dynamic shapes. Elias cautions that if there aren’t too many dynamic shapes, it may be better to generate separate specialized kernels for each and retain use of CUDA graphs and autotuning. Most of us were generally positive on this idea, but concerned about the implementation: dynamic shapes trace time, greater bug surface and lower generated code quality. Still, we can probably keep moving PT2 in this direction, but more data is also necessary.
Fine-grained dynamic dimensions. We want an API for marking dimensions as being explicitly dynamic. There are two primary users for this: (1) export, where we want to reject specialization/guards on dimensions that are explicitly dynamic as these usually indicate tracing problems and (2) eager mode power users, who want fine grained control over what dimensions should be compiled dynamically–e.g., to maximize performance, avoid unnecessary recompilation, or just diagnose why a model is recompiling when it shouldn’t. The fine-grained API is not intended to be the initial starting point for regular users: normal users should be able to not annotate anything and get intelligent results (see bullet above.) We went through a lot of API variations, but our current plan is to ship an API that lets you mark tensors as having dynamic dimensions, which affects how torch.compile does compilation. In the long term, we intend for eager mode to propagate these annotations using symbolic meta formulas (which is important for making this work across graph breaks). These annotations will NOT do anything if inserted inside a model; they only work at the “top level” where you trigger compilation. Some minutes for this discussion at https://docs.google.com/document/d/1aoIyYE8_6cYpWqS25thzVoIiKsT5aaUEOiiPwbIXt8k/edit Sherlock has an out-of-date prototype of the API at https://github.com/pytorch/pytorch/pull/93813
torch.constrain. When you mark a dimension as dynamic, you reject any user code which would constrain the dimension. But what if the constraint is that the dimension != 0; you would like a way to say that this constraint is acceptable. torch.constrain is an API that can be called inside the model to indicate these constraints should be accepted. Originally, Voz and Horace were imagining that you could put arbitrarily Python expressions in these constraints. We’ve negotiated to only allow a more limited set of constraints to start: min/max and multiple-of. We plan not to allow “relational” constraints that relate two separate symbolic variables: we simply assume that these are always OK. This means that export still needs some mechanism for communicating “implicit” guards (much in the same way we implicitly guard on the dtypes of all tensor inputs.) This API will likely also be used by unbacked SymInts. A big benefit of only allowing min/max constraints is they are easy to implement; you do not need to use Z3.
Unspecialize is adding too many float/int arguments. Horace noticed that forward graphs with dynamic shapes turned on have a lot of SymInt/SymFloat arguments. This is because we set specialize_int_float = False with dynamic shapes, but it turns out there are quite a few int/floats we SHOULD be specializing on. Horace is looking into this more.
SymInts/SymFloats in the backend compiler calling convention. In several conversations this week, we discussed whether or not Inductor should accept graphs that ONLY have Tensor inputs, or are int/floats valid inputs to the graphs. jansel and Natalia argued that it works well to turn int/floats into 0d cpu scalar tensors, and inductor supports this well. However, Horace pointed out that this does not work in general: if you have a backward graph for x.sum(), you need to do an x.expand(sym_int), where the SymInt isn’t necessarily derivable from any input to the backward graph. You can make it work, but the price is an FX graph that isn’t executable from Python anymore. So our current thinking is that we are doubling down on int/float inputs, unless jansel manages to change our minds.
Unbacked SymInts. Lots of progress: the stack at Get boolean masking to work with unbacked SymInts by ezyang · Pull Request #94523 · pytorch/pytorch · GitHub gets boolean masking working (and all but the last PR are passing CI). The general flavor of the work here is that you run into a lot of guards that fail on unbacked SymInts, but they all tend to be workaroundable one way or another. Edward next plans to tackle one of the internal models that needs this for mobile export, as well as getting range analysis going.
aot_eager training: 0 (unchanged). No regressions!
inductor inference: -8 (+2 WoW). The improvements are from hoisting from Natalia; there are also some new improvements from Natalia which should help with the remaining errors.
inductor training: still waiting on Horace to land his patch
Opinfo tests on symbolic shapes.
pytest test/test_proxy_tensor.py -k test_make_fx_symbolic_exhaustive - 553 passed (+3 WoW), 523 skipped (+1 WoW), 196 xfailed (+4 WoW). The increase in xfails are from some new RNG opinfos contributed by min-jean-cho.
voz: graph breaks, into dynamic to static guard rejection. Some minor rambling around with Z3.
Our north star: Dynamic shapes at feature parity with static shapes. Actively in discussions about getting back to “turned on by default, for some definition of default” for PT 2.1.
The branch cut for PyTorch 2.0 has come and gone. Training support was not landed to master in time for the branch cut, so it is unlikely to be working in the official PT2 release (on the bright side: inference functionalization made it for the branch cut! We think this fixed some inductor inference accuracy problems.) Stick to testing dynamic shapes on inference, sorry folks. A lot of the work this week was focused on inference export scenarios: there was quite a bit of progress on unbacked SymInts, the beginnings of a fine-grained dynamic shape API are in master and we also covered the 0/1 specialization problem in composability sync.
Unbacked SymInt progress. We made a lot of progress for unbacked SymInts support; most notably, value range analysis for unbacked SymInts has made it to trunk, so you can now use constrain_range on an unbacked SymInt to discharge guards (e.g., by marking an unbacked SymInt as >= 0). The entirety of CrystalDPR has successfully been traced end-to-end https://www.internalfb.com/diff/D43285838 (Meta-only), and I’m currently in the process of landing the necessary changes / cleaning up hacks. The biggest new discovered item we have to handle is when user code tests if a mask has any True elements in it, and if so, performs a boolean mask (otherwise, it lets all the elements through); to faithfully export this, we must use torch.cond, and we also must be able to join divergent shape variables together (into an unbacked SymInt). We also identified that guard free implementations of PyTorch must be allowed to change stride behavior sometimes; we will justify this under stride agnostic PyTorch (which says changes in strides are not allowed to affect program semantics.)
Fine-grained dynamic shapes. Voz has landed an initial version of fine-grained dynamic shape control in https://github.com/pytorch/pytorch/pull/94787 . This is a compromise API, where you still have to mark dynamic=True and assume_static_by_default=False, pending some refactors to bypass this. The PR as landed still uses backed SymInts, and only tests if a dynamic dimension is overconstrained at the end of trace time; switching it to use unbacked SymInts for export and better diagnostics for why guards occurred is upcoming work.
aot_eager inference: -1 (+1 WoW). The last holdout is vision_maskrcnn, which is due to an FX printing problem involving constants and inplace addition.
aot_eager training: 0 (unchanged). No regressions!
inductor inference: -5 (+3 WoW). We no longer have accuracy failures with dynamic shapes (we never root caused this, but I bet it’s inference functionalization related); pytorch_unet was fixed by more improvements from Natalia
inductor training: still waiting on Horace to land his patch
OpInfo tests on symbolic shapes.
557 passed (+4 WoW), 524 skipped (+1 WoW), 197 xfailed (+1 WoW). New OpInfo for _upsample_bilinear2d_aa among others.
ezyang: landing the rest of the CrystalDPR enablement fixes, presenting about how unbacked SymInt enablement works, then probably more on calling convention (but I also might want to work on some real model enablement for a bit? Depends on how much time I have)
Chillee: still landing inductor training
bdhirsh: per-dispatch key mode stacks and then torchquant/DTensor PT2 support
Export summit was this week. nonzero export support has hit master, give it a shot with capture_dynamic_output_shape_ops; with this, dynamic shapes work stream is deprioritizing export use cases for a bit. Training support is still not landed, this week we blame export summit for reducing coding time.
Worse is better unbacked SymInt. Last week, we showed off a PR stack with all the tricks for avoiding guards in core PyTorch code. Well, people didn’t like having to change their code to carefully avoid guarding on 0/1. So we came up with a new plan: Steps forward for 0/1 specialization (worse is better) - Google Docs that involves doing a lot less work, as we will just unsoundly assume that unbacked SymInts cannot be 0/1 (the observation being that: if code works for any value of N>1, it usually works for N=1 too.) The rest of the non-controversial unbacked SymInt changes have landed to master (in particular, value ranges are in! Lots of opportunity here!), and @ezyang is moving back to non-export related dynamic shapes work. To experiment with item()/nonzero() support, you must set config flags capture_scalar_outputs and capture_dynamic_output_shape_ops to True. Inductor does NOT support nonzero, so this is mostly only useful for export.
Delta benchmarking. You can now easily run a sweep for static/dynamic and compare their frame time / graph breaks with Utility for running delta comparisons between two flag configs. Feel free to add any more comparisons to the script as necessary.
State of real world model enablement. I’d like to keep this section around from week-to-week. Not exactly sure how to setup the numeric metrics yet, stay posted. We don’t have a stack ranking of how important any given model is, but there are not so many so far so I think it is safe to say they are all important.
LLaMa (https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/) - one of the researchers reached out to us internally on Jan 17 about speeding up inference, but at the time it wasn’t working. Some of the known problems: failing to generate dynamic kernels because split reductions are size specialized and LLaMA hits them, some other problems which are fixed on HEAD. Next steps: put LLaMA into torchbench and run it end to end; can also do https://www.internalfb.com/phabricator/paste/view/P600348954 (Meta only) which is a more minimal repro, although I think once you get far enough it’s missing some imports.
OpenNMT (OpenNMT doesn't work with dynamic torch.compile · Issue #93468 · pytorch/pytorch · GitHub) - there are two parts. First, vince62s has a minimal repro involving arange that doesn’t compile correctly; this is due to dynamo over-specializing integer inputs into graphs if they’re too small (specialize constant heuristic). Second, we need to actually try running dynamic=True on the entirety of OpenNMT, which hasn’t been done yet.
InstructPix2PIx (InstructPix2Pix) - requested from XR Labs via @wconstab ; 2D image dynamic inputs. No initial investigation. Please file a GitHub issue to track it too.
Fused boolean mask update (https://fb.workplace.com/groups/1075192433118967/permalink/1204060330232176/ - Meta only) - Fei asked why x[bool_mask] = y requires an DtoH sync, and Soumith promised that eventually dynamic shapes would support fusing this all together. Let’s make sure this happens. (It may be simpler to pattern match this and replace it with torch.where though!)
Graph breaks on master. -3 (-1 WoW). The regression is hf_Longformer and AllenaiLongformerBase on master, non-function or method super: <slot wrapper '_setitem_' of 'collections.OrderedDict' objects>, @voz is investigating. To catch regressions, we’re going to add expected graph break counts to CI; @wconstab is going to do this.
Tracing cost of enabling dynamic shapes (aot_eager). Mean: 21s (-7s FoF), Max: 254s (-406 FoF). Two weeks ago I said I was going to explain what these stats are and forgot . Here’s the explanation I promised. What we would like to measure is how much more expensive doing tracing with symbolic shapes is, since if it is substantially more expensive in absolute terms our users won’t want to have it turned on by default. So what we do is we run aot_eager accuracy benchmark with and without benchmarks, and record how long we spend inside frame compilation. We then compare the difference and take the mean and max. Improvements from last two weeks are likely from better constructor short circuiting (no longer decomposing empty.)
What’s made it to master since last time?
I’m retiring this section, but holler if you found it useful and I’ll start doing it again.
What’s coming next?
ezyang: no longer working on unbacked SymInts, back on model enablement. Will spend some time ramping on inductor (mood: no docs WRYYYY). Still planning to untangle the int-inductor calling convention problem
Chillee: still landing inductor training. Maybe will write another Inductor explainerdoc.
bdhirsh: aotautograd refactor for training export, as well as per-dispatch key mode stacks and then torchquant/DTensor PT2 support
jbschlosser: pivoting to sparse stuff, will be omitted from list here
voz: follow through on fine grained dynamic shapes, follow up on graph break regression, constraints
Training support has hit master… sort of. Horace’s patch to add training support passed CI and is landed, but it turns out our testing was insufficient and you need to manually turn on torch._functorch.config.use_dynamic_shapes = True for it to actually work. This is fixed in Fix training enablement in AOTAutograd by ezyang · Pull Request #95975 · pytorch/pytorch · GitHub which isn’t landed yet. A large number of models pass, but there are also many models which fail or have accuracy failures, we plan on burning these issues down shortly.
Handling int/float inputs/intermediates in Inductor. One of the major points of contention are how exactly non-Tensor ints/floats supposed to be passed to Inductor. Should they be passed as SymInt or 0d tensors? We’ve finally resolved the question at Handling int/float inputs/intermediates in Inductor - Google Docs The overall idea is that sizevar computation should be expressed as non-Tensor computation (or, more specifically, with sympy expressions), but everything else should just be Tensor compute, for ease of lowering. In practice, this means ints are passed as ints (as we must track their sympy expressions in case they are used in a sizevar compute), but we have made a policy decision that input floats can NEVER be used sizevar compute, and thus they can always be passed as 0d tensors.
Int unspecialization actually works now. Previously, there was a knob specialize_int_float, which, hypothetically, if set to False, allowed you to generate Dynamo graphs which didn’t specialize on int/float inputs. In practice, this knob didn’t actually do anything, as every integer between 0-17 was specialized anyway. In practice, this matters; for example, overspecialization in OpenNMT doesn't work with dynamic torch.compile · Issue #93468 · pytorch/pytorch · GitHub was due to Dynamo deciding that a batch size of 10 was small enough to specialize on. Make int unspecialization actually work fixes that problem. However, this in the process uncovered a pile of bugs in Inductor regarding unspecialized ints. Right now, int unspecialization is not turned on by default but we intend to shift to it soon, allowing for regressions in CI.
We now allow implicit specialization via int conversion. Previously, if you ran int(symint), we would raise a warning, saying that this would cause a specialization, and if you really wanted it, you should explicitly guard_int. We have now relaxed this restriction: we will implicitly convert SymInts to ints and introduce guards as necessary. This switch is profitable because there are a number of APIs which cannot, even in principle, support dynamic shapes, and so allowing these implicit conversions make these APIs work (as opposed to fail as we do today).
Guards depending on unbacked SymInts.@tugsbayasgalan took the new nonzero export support in master, and he noticed one major gap: in some cases, we would generate guards that depended on unbacked SymInts, which is a big no-no, because guards must be executed at the very beginning of a model, but an unbacked SymInt may only become known midway through execution. The fix for this Don't generate guards that refer to unbacked SymInts by ezyang · Pull Request #95732 · pytorch/pytorch · GitHub revealed that there a number of guards with the odd property: (1) if you replace the backed shape variables (s0, s1, …) with their size hints, you can statically determine what the guard should evaluate to given the example inputs, but… (2) without this replacement, it’s not clear if the guard is true or not. For example, Ne(36*i0, 36) is trivially True when i0 > 1, but the real expression in context is Ne(i0*((s2//2 - 1)//8)**2 + 2*i0*((s2//2 - 1)//8) + i0, ((s2//2 - 1)//8)**2 + 2*((s2//2 - 1)//8) + 1) (which Tugsuu also thinks is True, but sympy can’t figure it out.) Another example is Eq(i0*s3**2, 9*i0), where this should result in a guard that s3 = 3 but sympy once again cannot figure it out. Our current hypothesis is that many of these shape variables are actually static at the end, but at the time the guard we don’t know what they are; so either deferring the checks till later or encouraging users to assume_static_by_default = True should help. Tugsuu will validate this next week.
PSA: size_hint vs evaluate_expr. We found out this week that some internal teams are making use of ShapeEnv, and were misusing evaluate_expr. Contrary to what its name suggests, this not only evaluates an expression, but it ALSO installs a guard. If you want to peek at what the value of the expression is without guarding, you should use size_hint.
State of real world model enablement.
Mark Saroufim has tentatively volunteered to add LLaMa and InstructPix2Pix to torchbench, which will help us track whether they work or not with dynamic shapes.
OpenNMT’s arange minimal repo no longer overspecializes, but it fails in Inductor now with assert isinstance(numer, int) and isinstance( at
torch/_inductor/utils.py:83. This failure also affects fastNLP_Bert, speech_transformer and yolov3 inductor inference
No updates: MaskRCNN, Detectron2, wav2vec2, fused boolean mask update
The numbers:
Model status on master.
aot_eager inference: 0 (+1 WoW), Joel’s PR made it in.
aot_eager training: 0 (unchanged). No regressions!
inductor inference: -4 (+1 WoW). swin fix made it in.
inductor inference unspec: -10 (NEW!). This number is tracking inductor inference with specialize_int = False now that unspecialization actually does something. We plan to subsume the old inductor inference number with this one, as unspecialization is important for avoiding overspecialization in graph breaks in practice. We should probably also switch the aot_eager stats to this as well.
Graph breaks on master. 0ish (+3 WoW). A sweep on 2/23 revealed a extra graph breaks on hf_Longformer and AllenaiLongformerBase but Voz manually confirmed that the static model also graph breaks. @wconstab added ability for CI to record graph breaks Add dynamo graph break stats to CI by wconstab · Pull Request #95635 · pytorch/pytorch · GitHub so hopefully we can just start testing the number of graph breaks in CI and ensure we avoid regressions this way. Tracing cost of enabling dynamic shapes (aot_eager). Mean: 20s (-1s WoW), Max: 240s (-14s WoW). This looks within noise.
Known problems
Inductor guards are silently discarded; this could cause accuracy problems
CI is not testing if we actually successfully generate dynamic code, so we could silently regress this (right now, we validate the generated code by manual inspection)
We are not testing performance of dynamic shapes code; it could be heinously slow (fixing this is blocked on GCP dashboard runs)
Minifier does not work with dynamic shapes
Split reductions in Inductor do not work with dynamic shapes
Python profiling gives misleading results for what is causing slowdowns
What’s coming next?
ezyang: probably a mix of unspec int / training burndown, and discovering more issues from our E2E models. The assert isinstance(numer, int) and isinstance( is a particular blocker for OpenNMT.
Chillee: returning to dynamic shapes, probably something symbolic reasoning related, also some training burndown
msaroufim: I asked Mark to add LLaMa and InstructPix2Pix to torchbench, we’ll see if he gets to it or not
bdhirsh: still aotautograd refactor for training export, as well as per-dispatch key mode stacks and then torchquant/DTensor PT2 support (was working on reference cycle issue this week)
Training support is now properly fixed on master; modifying functorch config is no longer necessary. Some Inductor bugs were fixed, some are still pending.
specialize_int = False (aka --unspecialize-int) is now the default in CI (with some regressions), and soon will defaulted for regular users too.
Dynamic shapes are working for whole graph inference (e.g., BERT), but we often overspecialize when there are graph breaks. Two weeks ago we fixed overspecialization on size ints that were carried across graph breaks (when specialize_int=False); a similar fix for torch.Size carried across graph breaks is pending at Don’t specialize torch.Size with specialize_int = False
A reminder that if you are debugging overspecialization problems, you can slap a torch._dynamo.mark_dynamic_dim(tensor, dim) on the dimension you expect to be dynamic to see if it actually is dynamic or not. You’ll still have to diagnose the problem, we’ve recently been having success with extra logging on ShapeEnv, c.f. https://github.com/pytorch/pytorch/pull/95848
Stuff that happened:
Some symbolic shapes adjacent news:
The case of flaky dynamo export tests. This is not exactly symbolic shapes related, but the debugging session was prompted while I was working on some symbolic shapes related changes. This bug is of interest to anyone working with Dynamo: Debugging story: The case of the flaky Dynamo export tests
Fallthrough works correctly with PyOperator. If you use functorch control flow operators for export, you should be happy to know that PyOperator fallthrough now works (see Correctly resolve dispatch keys for PyOperator stack), which should solve some problems that Angela Yi was working on unblocking.
Tons of bugs fixed, still lots more bugs. Some highlights:
Export is getting a higher level constraints API. This adds a new constraints kwarg to export, which lets you declare things like “these dimensions are dynamic” (dynamic_dim(y, 0)). See Add higher level export constraints api for the details.
No updates: MaskRCNN, Detectron2, wav2vec2, fused boolean mask update
How far away from dynamic shapes “shipping”? Soumith defines shipping as “we show meaningful end-to-end speed ups in training due to dynamic shapes” (possibly with s/training/inference/ as a milestone on the way to this goal), but at the same time, we are in the business of creating generic infrastructure that works for everything, not just cherry-picked models.
On training, the metric here is difficult to define, because models don’t really have dynamic shapes. So to evaluate real world models, we would really have to take models that do have dynamic shapes in training (e.g., can be observed by the fact that otherwise they blow out the compile cache.) We don’t have this list of models: we need to sweep the benchmark suite and find out (although there’s a decent chance models involving bounding boxes like detectron2 and MaskRCNN are likely to be on this list). Plus, you have to make sure you’re running enough iterations, with real enough data, to actually exercise this data dependence! However, it’s possible things are working today already, we just don’t actually have the data.
On inference, the value add of dynamic shapes is much easier to articulate: people want to vary batch size (for adaptive batching), sequence length (because text input is variable size) and image size (ditto), and we have already shown dynamic shapes works end-to-end for models like BERT. The flip side of the coin is if dynamic shapes is “shipped by default”; and this involves adaptively turning on dynamic shapes when we detect situations where we have potential to blow out our compile cache–this is probably a week or two of full time work to finish off.
aot_eager inference: -1 (-1 WoW). The regression is a new sympy RecursionError in vision_maskrcnn induced by unspecialize_int=False when running reshape(torch.empty(s1, (s0 + 1)//2, 2), (s1, s0)). Logs
aot_eager training: -2 (-2 WoW). The regression are also two sympy RecursionError induced by unspecialize_int=False. The botnet26t_256 looks like the same cause (reshape) as the vision_maskrcnn, but eca_botnext26ts_256 looks like some sort of modulus problem. Logs
inductor inference: -4 (+6 WoW, or unchanged, depending on how you count it). We regressed this stat with specialize_int = False, but we fixed most of the regression in time for the report. We did one trace: volo_d1_224 is now fixed, but convit_base is failing with a new error “TypeError: Cannot convert symbols to int”
inductor training: -9 (NEW!). Training is enabled in CI! The bulk of the current failures are either 'float' object has no attribute '_has_symbolic_sizes_strides' (this is due to AOTAutograd sending graphs with SymFloat inputs, contrary to inductor’s input contract). There is one accuracy failure with rexnet_100; however, this model is known to be flaky accuracy with static shapes too.
Graph breaks on master. 0ish (unchanged). hf_Longformer and AllenaiLongformerBase are still diverging intermittently. Graph breaks will be in CI and we will resolve this one way or another.
Tracing cost of enabling dynamic shapes (aot_eager). Mean: 15s (-5s), Max: 168s (-72s WoW). Not really sure where the speedups are coming from, but we’ll take it!
Repro command: benchmarks/dynamo/run_delta.sh --backend aot_eager --devices cuda --cold-start-latency --ci
Guards generated by inductor in backwards don’t do anything. We’ve known this for a while, but this has started showing up for real in bug reports. Usually, we didn’t want the specialization anyway, but this bug means that instead of getting recompiles, we will just blindly run code at the wrong size; sometimes you still get an error (like size mismatch between 14817 and 14797).
Minifier with dynamic shapes doesn’t work! Even our users have noticed.
The export team has been asking about how to export MaskRCNN, and in particular Yidi Wu has submitted a PR requesting to add while loops to our control flow operators. The while loop is motivated by the fact that MaskRCNN iterates through bounding boxes to perform an expensive prediction, and they need early exit as soon as they’ve found what they’re looking for.
I looked into what kind of dynamism folks wanted for InstructPix2Pix, and it seems like they want to dynamically vary the image height/width. It is not clear if we can actually easily support this; I don’t understand diffusion model architecture well enough to know how to compile a size agnostic model; it seems like you need to make actual architecture changes to work on different sizes.
No updates: LLAMA, OpenNMT, Detectron2, wav2vec2, fused boolean mask update
PyTorch core offsite happened! Some things we discussed:
Split reductions. We have a strategy for dynamic shapes split reductions now. Split reductions refer to a performance optimization when compiling reductions where the non-reduced axis is too small for us to fully occupy all blocks on GPU by simply assigning each reduction to a block. When the number of elements to reduce is large, we want to split these large reductions into smaller reductions for better occupancy. Split reductions substantially improve performance when they apply. Currently, split reductions cause us to specialize on all of the input shapes involved; to support dynamic shapes, we should instead guard only the determination if an axis is large or not. We may perform this as part of an Inductor-specific decomp, if it is simpler to do so. Thanks Natalia for guidance on how to do this.
Supporting while loops as control flow operator. Yidi Wu wants to while_loop to our control flow operators set: [functorch][experimental] Support while_loop in eager_mode by ydwu4 · Pull Request #96899 · pytorch/pytorch · GitHub I didn’t like it. We spent a bunch of time discussing this in the offsite, and we settled on this: there is utility in pushing control flow with restrictions to Inductor, as it gives Inductor opportunities to optimize (instead of forcing a hard barrier before and after the control flow.) The important thing is to restrict the operator sufficiently, so that it can be treated as “just a complicated operator”. Furthermore, to propagate the operator all the way to Inductor, all of our passes must know how to handle it (most notably, autograd, functionalization and batching). To put a control flow operator into PyTorch proper, it must live up to this standard; otherwise it should just be treated as some ad hoc, inference export only unblocker.
Asserts. We spent some time discussing how asserts (and debug logging) should be implemented in our IR, prompted by Tugsuu’s work in export on the topic. The challenge is twofold: first, asserts are side effectful operations, but the current design of our IR is functional and would permit us to DCE all asserts. Second, we don’t want asserts/debug logs to interfere with normal optimizations that we are doing in programs. Our current thinking is that we will do a GHC-style “world token” to represent asserts and debug logs. In short, every assert/debug log will take a synthetic, zero-size “world token” tensor as input, and produce a new world token as output. The overall graph takes a world token and produces a world token. The resulting graph looks like this:
def f(x, world0):
b = torch.any(x)
world1 = torch._assert(b, world0)
y = x + 1
return (y, world1)
World tokens done in this style enforce a consistent ordering between all asserts and logs (it is likely confusing to users if log messages get reordered) and don’t require any special handling from optimization passes (as these are just “normal” data dependencies.) No new concept of control dependencies is added.
aot_eager inference: -1 (unchanged). Still vision_maskrcnn sympy error from reshape(torch.empty(s1, (s0 + 1)//2, 2), (s1, s0)).
aot_eager training: -2 (unchanged). Still botnet26t_256 and eca_botnext26ts_256.
inductor inference: -6 (-2 WoW). The regression in PegasusForCausalLM and PegasusForConditionalGeneration is from the bug fix to avoid specializing on torch.Size. These models error in the same way as convit_base: “TypeError: Cannot convert symbols to int”
inductor training: -2 (+7 WoW). This was where most of our activity was this week! There’s only two failures left: pytorch_unet (TypeError: unhashable type: ‘SymInt’) and tf_efficientnet_b0 (NameError: name ‘s1’ is not defined)
Graph breaks on master. Will’s graph break infrastructure is checked into master, but not yet running on dynamic shapes. The also appear to be turned off for aot_eager. I did a run with them turned on for dynamic shapes. https://hud.pytorch.org/pr/97107
inductor: -7 (NEW!). Weirdly, using inductor as the backend seems to change dynamo behavior. These models did worse: XLNetLMHeadModel, poolformer_m36, visformer_small, volo_d1_224, drq, functorch_maml_omniglot, maml_omniglot. We also had one model do better (less graph breaks): hf_Reformer
This was a sleepy week. There’s a lot of activity going on in various dynamic shapes bugs on the bug tracker, though less fixes than I would have liked.
puririshi98’s GCN NeighborSampling minimal test is only slightly faster with static compile (and only after fixing graph break); dynamic shapes is slower even with graph break fix, it could be split reductions, but even with static there is not much payoff.
aot_eager inference: -1 (unchanged). Still vision_maskrcnn sympy error from reshape(torch.empty(s1, (s0 + 1)//2, 2), (s1, s0)).
aot_eager training: -2 (unchanged). Still botnet26t_256 and eca_botnext26ts_256.
inductor inference: -7 (-1 WoW). The regression is tf_efficientnet_b0 from https://github.com/pytorch/pytorch/pull/97099; this is a case of temporarily breaking things to move globally in a better direction
inductor training: -1 (+1 WoW). pytorch_unet was fixed, leaving tf_efficientnet_b0 (NameError: name ‘s1’ is not defined)
Graph breaks on master. Sorry, CI is still not updated to do dynamic, maybe next week. We think the graph breaks are not super high priority at the moment, unless they are also affecting performance.
Dynamic shapes hits CI. Dynamic shapes is now on the new experimental performance dashboard, thanks to the new CI-based GCP A100 infrastructure it was really easy to add a new configuration. We’re switching our weekly stats reporting to it. One thing to note: this runs dynamic shapes in a non-standard configuration where ONLY batch size is treated as dynamic. The performance and compile time is quite a bit worse if you do “YOLO everything dynamic shapes” with dynamic=True. By the way, there’s also now a script to summarize performance from a CI performance run if you want to do a one-off experiment.
Multi-level cache / shape env. Voz, Natalia and I have begun discussing in earnest how exactly to setup multi-level cache and shape env. Here is our current thinking:
It’s not just a two-level cache. We need the ability to use guards to switch between several possible artifacts in several situations: (1) in backwards, in case compiling the backwards graph results in more guards than were initially installed in forwards, (2) in backwards, in case the passed in gradient is not contiguous (e.g., channels last gradient) and changes the validity of the compiled backwards kernel, (3) in forwards, when compiling graphs with operators that have data-dependent output shapes. Originally, our dogma was that such operators should result in graph breaks until inductor learned how to compile them (much later in the future). However, graph breaks inside deeply inlined functions are extremely bad for performance, since if you have the call stack f1-f2-f3 and f3 graph breaks, you end up having to compile six separate graphs: f1-pre, f2-pre, f3-pre, f3-post, f2-post and f1-post. There is no opportunity to fuse among these graphs. A post-dynamo, pre-inductor notion of graph break would allow inductor to guard on the specifics of the data dependent shape, while still permitting these fusion opportunities.
No replacements after the first level. A big complication with a generalized multi-stage ShapeEnv is that we have a large number of SymNodes floating around, whose saved sympy expressions automatically get updated if we discover a new replacement (e.g., mapping s0 to 3). Although there are some complicated schemes that can handle this in full generality, our current thinking is that we will restrict replacements to the first level. For later levels (e.g., in backwards), we can only add guards, we will never add new replacements. In practice, this should work well, as backward shapes match their forwards, so the only new guards will just be Inductor-level guards on alignment, etc.
detectron2 - I did some initial investigation on detectron2_fasterrcnn_r_101_c4 and noticed it is failing on translation to torch._assert. (cc Tugsuu)
An internal multimodal model (Meta only) is 5x slower on Azure A100 but 5x faster on devgpu A100. Weird! It also seems to infinite loop on the devgpu A100 if you remove the graph breaks. I have the go ahead from the research scientist to publish a sanitized version of the model without weights, coming soon.
T5 is fast now. In T5 model taking too long with torch compile. · Issue #98102 · pytorch/pytorch · GitHub, HuggingFace was trying out torch.compile on an E2E T5 model. Their initial attempt was a 100x slower because their model was dynamic and repeatedly recompiled. After fixing a long string of issues (switch to dynamic=True, patching in their change to exclude compilation time from iter/s calculation, eliminating guards on NN parameters, reducing inductor induced recompilation), we are now 2x faster than eager mode! A great result.
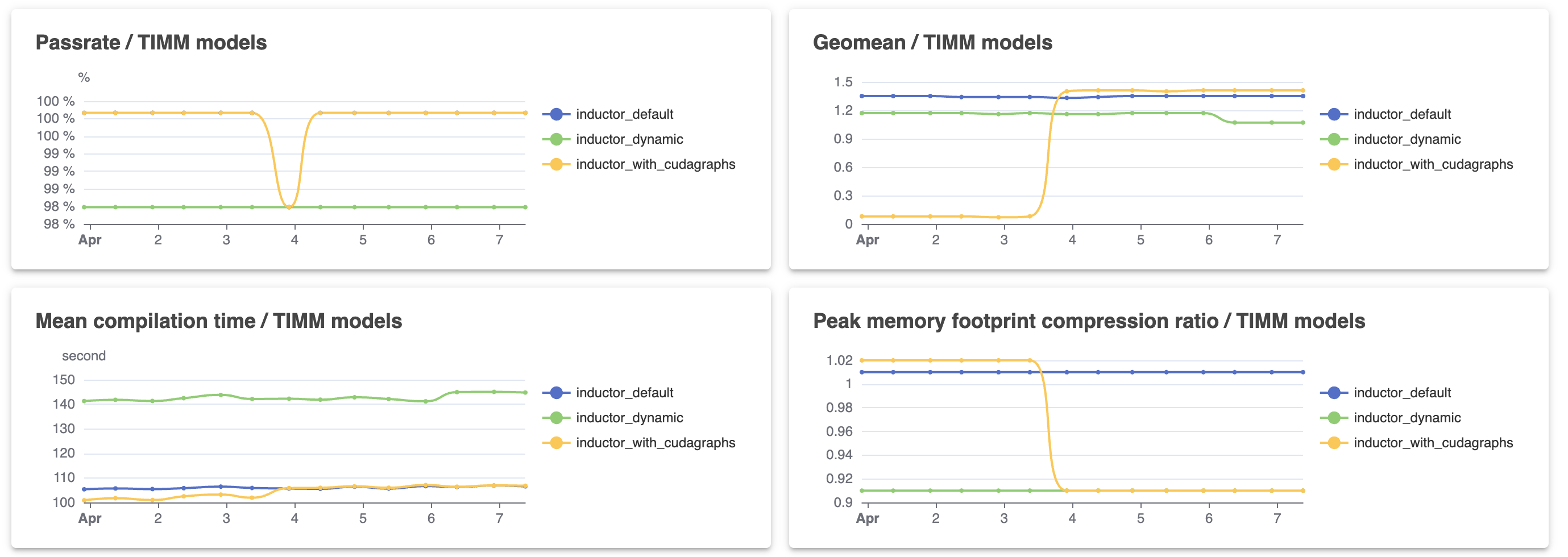
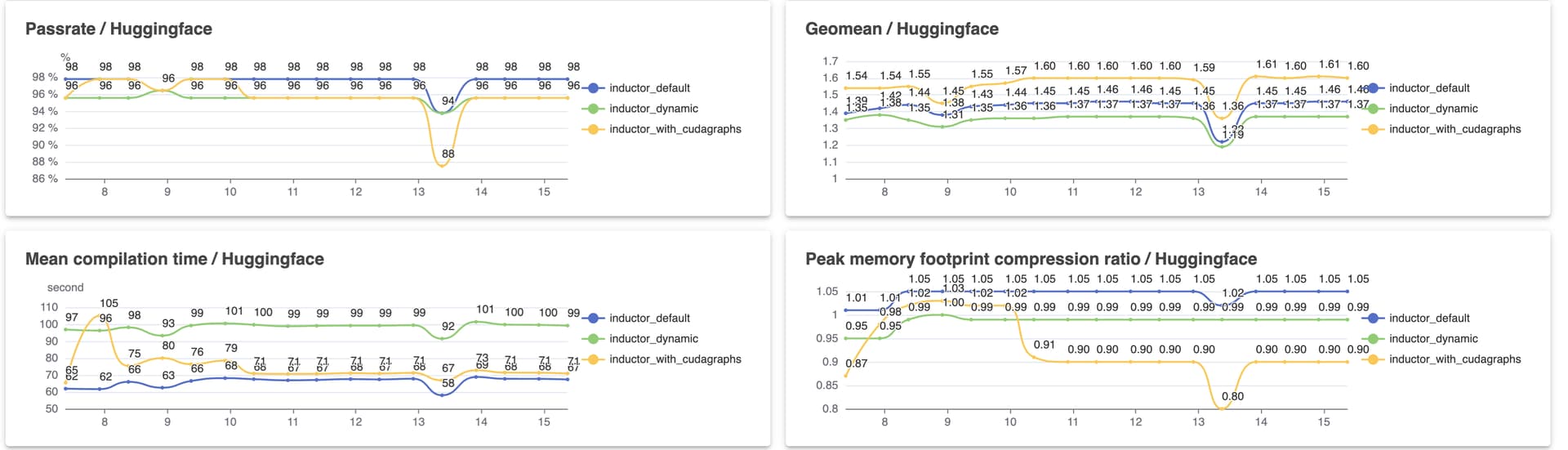
Dashboard changes. We changed some of the methodology of our performance runs, mostly making it stricter. In particular, we now require sequence length in huggingface to be dynamic (previously, we only marked batch dimensions as dynamic), and we now require batch dimensions to be compiled dynamically (raising an error if the batch dimension gets specialized.) These did not materially affect our pass rates, but enabling dynamic sequence length on huggingface did result in an end-to-end perf regression. We also switched accuracy CI to dynamic batch only, which eliminated most of our outstanding CI failures. One potential methodology problem still in our performance runs is we do not propagate dynamic dimensions; thus, if a model has a graph break, all subsequent graphs will be compiled statically. We need to better understand the extent of this problem.
mark_static. There is now a mark_static function, which is analogous to torch._dynamo.mark_dynamic, except that it forces a dimension to be compiled statically. So overall, your tools for controlling dynamism are: dynamic=True makes everything dynamic (but duck sized), mark_static lets you force things to be static, assume_static_by_default makes everything static, and mark_dynamic lets you force things to be dynamic. Once @voz lands automatic dynamic detection on recompilation, we will switch assume_static_by_default to be the default and you can either explicitly mark_dynamic, or wait for a recompile to induce dynamism. Making everything dynamic by default would be relegated to situations where you absolutely do not want to recompile.
Inductor optimization ablation study. Check out A small inductor optimization ablation study for a better understanding of where the performance gaps between dynamic shapes and not are coming from.
A new strategy for inductor guards. Last week, we proposed that in forwards, we may need to have a notion of an “inductor” graph break, which would permit inductor to install guards on otherwise dynamic values that we cannot float to the top level. While this is still necessary in principle, our new thinking is that we should rarely need it: most guards from inductor arise from optional optimizations, and what we should do is just make sure to disable these optimizations when we cannot conveniently install a guard.
Guard CSE. Yukio has a PR https://github.com/pytorch/pytorch/pull/98488 for running CSE at a Python-level on guards. It shows a 2-4% across the board performance improvement. Nice! There are some correctness issues that must be ironed out before landing.
Nested tensor metadata format change proposal. Me, Joel, Alban and Basil worked out an alternate proposal for nested tensor metadata representation, motivated by Joel’s difficulties in modeling nested tensor contiguity with symbolic shapes, as nested tensor stores strides in a tensor, which means there is no straightforward way to actually compute if something is contiguous without something data dependent. The updated proposal has several parts: (1) nested tensor distinguishes dim=0 (the batch dimension) to be the only dimension by which jagged dimensions can vary; in other words, a nested tensor can always be modeled as a list of dense tensors; (2) after the batch dimension, there may be any number of inter-mixed dense/ragged dimensions, followed by a suffix of dense dimensions only; (3) only the suffix of dense dimension and the right-most ragged dimension can be non-contiguous; the batch and inter-mixed dense/ragged prefix MUST be contiguous; (4) this suffix has strides represented as ordinary integers without any raggedness. The general idea is to understand under what circumstances strides can be represented without hitting raggedness, and allow discontiguity on those strides ONLY. Meeting notes at https://docs.google.com/document/d/1BFNKz1XziYbhnBo48kJ9_DzmiwPgcXREpH3La6JCCQU/edit#
CM3leon-760M (this is that Meta only, name is OK’ed to share) - OK, so it was a roller coaster this week. It turns out that this model wasn’t ever 5x faster; instead, we had missed that the units had changed from ms to s (oof!) Benchmarking with torch.profiler suggested that guard overhead was a major problem, and we shelved it for now. However, work on T5 identified a number of problems; so at the end of the week I gave CM3Leon and we now see a very slight improvement (at generate_size=10, we go from 150ms to 131ms.) Kineto profiles suggest CPU overhead is still an issue (see below), though TBF Kineto always thinks CPU overhead is the problem (due to the fact that the profiler distorts CPU overhead.) One hope is that upcoming attention optimization by jansel should help.
CI skips (aot_eager inference/training; inductor inference/training): 0, 0, -1, 0 (+1, +2, +6, +1 WoW); the improvements are primarily due to switching to dynamic batch only (in other words, the bugs still exist, but we expect realistic usage not to care about them as they result from making dimensions dynamic that don’t need to be dynamic)
Assume static by default is default.Automatic Dynamic Shapes by voznesenskym · Pull Request #98923 · pytorch/pytorch · GitHub prefigures our eventual approach for enabling dynamic by default: we assume everything is static, and then when we notice that we recompiled because a size changed, we compile with the dimension dynamic. This means dynamic=True results in more recompilations than it did before (because you will compile once static and then once dynamic), but you now you only pay (in terms of bugs and performance) for dimensions that are actually dynamic. If you want to skip the recompile, you still can use torch._dynamo.mark_dynamic to force a dimension to be compiled dynamically; you can also set assume_static_by_default=False to go back to the “YOLO everything is dynamic” flow.
Backward retracing is no more! Read https://github.com/pytorch/pytorch/pull/99089 for all the details, but the short version is we now share ShapeEnv between backwards and forwards, which should improve the precision of backwards graphs we compile. Unfortunately, this also regresses accuracy on yolov3, which we are investigating.
Big improvements in symbolic shapes logging. You can use TORCH_LOGS=torch.fx.experimental.symbolic_shapes to see logs about symbolic shapes. Importantly, we now report both the user and framework code that caused a guard to be added at INFO logging; this is extremely useful for debugging overspecialization. See Support large negative SymInt by ezyang · Pull Request #99157 · pytorch/pytorch · GitHub for some sample logs.
Whoops, we were measuring the wrong thing. Big kudos to @ngimel, who noticed that when running the performance benchmarking script, we were generating entirely static kernels, even when running --dynamic-shapes. It turns out that our mark_dynamic tags were getting lost before actually making it to torch.compile region; combined with assume_static_by_default, this meant that we were compiling everything with static shapes–our performance difference was solely attributable to us disabling certain optimizations when dynamic_shapes configuration was true. We fixed this on Apr 23 with Preserve mark_dynamic when cloning inputs (with Huggingface getting a further fix on Apr 25), which ended up wiping out some of our perf gains earlier this week (which were mostly a function of making things perform well if everything actually was static) as well as our compile time improvements from last week (ouch!) To prevent this from happening in the future, we plan to also count the number of symbols in compiled subgraphs and track this number in performance CI.
Accuracy repro extraction/minifier. A lot of the remaining pass rate issues are due to accuracy problems, so Edward has pivoted to working on the accuracy repro extraction and minifier to help us make progress debugging these issues. A general overview of our approach is at Improving accuracy repro extraction - Google Docs . We have a soon to land stack at https://github.com/pytorch/pytorch/pull/99834 which adds the ability to serialize real data to accuracy minifier (instead of regenerating random data in the repro), and also provides the ability to perform a fast, bit-exact checksum on data (which is useful for detecting, e.g., nondeterminism.)
As part of the minifier work, we took the BC-breaking change of switching the backend calling convention back to real tensors. This means that if you are a direct Dynamo backend (as opposed to living behind AOTAutograd), you will now get real tensors from Dynamo. To fakeify them, detect_fake_mode and then reconvert them from fake tensor.
TORCH_LOGS=dynamic. You can now conveniently get dynamic shapes logs without typing torch.fx.experimental.symbolic_shapes thanks to rename sym_shapes logger to dynamic
CI skips. 0, 0, 0, -2 (0, 0, +1, -1 WoW); yolov3 is fixed; levit_128 is an accuracy failure that only happens on A10G, interestingly, it is already skipped on aot_eager (but not inductor). sebotnet33ts_256 is flaky.
As mentioned previously, the results this week regressed because we fixed a methodology problem in the benchmark suite (where we weren’t actually generating dynamic kernels). In general, our pass rate was not affected too much, but we lost most of our performance improvements from mid week (which makes sense, because these improvements were mostly “if everything actually is static, do the fast static path”–clearly these improvements would be overrepresented if everything was static!) The other important thing to note is that we turned off dynamic sequence lengths on Huggingface (as it did not work for most models; see the dip on the 23rd); we will work to turn this back on, which should result in another regression next week.
Here are the top line metric changes from this week:
This month on HUD. It’s been a month since we’ve enabled the GCP A100 runners for performance testing, so I’ve also included the month long graphs for dynamic shapes only. Some important dates in the graphs: on Mar 29 we switched from trying to make everything dynamic, to making everything static (remember; at the time, we thought we were keeping batch size dynamic, but actually we were wrong), and on Apr 24 (the very last data point), we fixed it to actually have dynamic batch size.
Big grind for dynamic by default.@voz reports that enabling dynamic by default (or, more specifically, static by default but automatically turn on dynamic on recompile) has turned into a bit of a slog. Some of the reasons: (1) people have been adding new test files to the Dynamo test suite, but those tests have not been simultaneously run with dynamic shapes so we were running blind there, (2) it’s not risk free to recompile into dynamic shapes (our plan to derisk here is to remove dynamic_shapes=True but keep automatic dynamic false to start) and in practice some things broke on the full PyTorch test suite + dynamo, (3) there a lot of conditionals on dynamic_shapes scattered throughout the codebase and they all have to be rewritten not to do this.
Accuracy work on dynamic shapes should be unblocked by improved accuracy minifier. We’ve fixed one bug with the help of the new minifier infra described at Major updates to the after AOT accuracy minifier! ; hopefully we can nail more!
New benchmarks. Edward’s focus on this week was adding new benchmarks. We now have autoregressive generation benchmarks (hf_T5_generate, cm3leon_generate, llama is now enabled in our benchmark suite, and coming soon are some new GNN benchmarks as well as working vision_maskrcnn (having solved its eager mode determinism problems.) This finally makes good on our promise last month to add a dynamic-shapes oriented set of benchmarks for more fine-grained tracking. Once these benchmarks stabilize we will report for these models specifically in our updates. What’s still missing? We’d also like to get detectron2 working, and it would be good to have llama_generate and gpt2_generate (broken due to HF bug.) There’s also not much representation from generative image models at the moment. We also want to be tracking HuggingFace’s compile experiments closely. The new benchmarks are also quite broken with torch.compile, more bug fixing required!
Translation validation. Yukio has posted an initial translation validator for our symbolic shape reasoning. How exciting!
Hint sets. One hypothesis we have about the perf regression from State of symbolic shapes branch - #54 by ezyang is that we are nixing optional optimizations that, actually in practice, would be OK to apply. (A simple example is 32-bit indexing, though Natalia tells us that this one is unlikely to matter.) If this is true, we could potentially allow for more optimizations by allowing for hint sets: rather than having only one hint when inductor compiles a graph, we maintain a hint for EVERY concrete instantiation of the size vars we have seen so far. Optional optimizations that generalize to all instantiations continue to be allowed. No one is working on this yet, and we don’t know how much it will buy.
CI skips. -2, -1, 0, -2 (-2, -1, 0, 0 WoW). The new failures are from new models (cm3leon_generate, hf_T5_generate and llama) which we’ve enabled in torchbench.
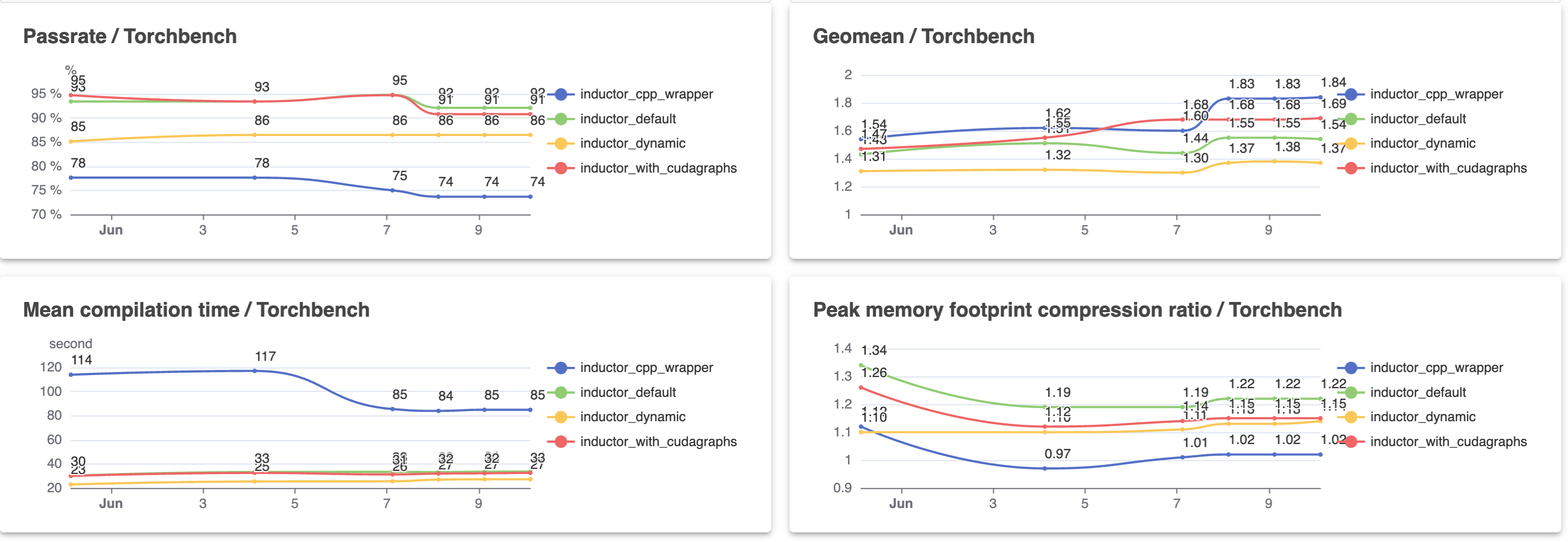
Improvements in torchbench and timm_models (e.g., alexnet, squeezenet1_1 from torchbench) stem from models with previously horrible performance, no longer having horrible performance. Based on discussion with @ngimel, https://github.com/pytorch/pytorch/pull/101602 is likely the reason, as static shapes is incorrectly eliding indexing bound device asserts, but dynamic shapes is not eliding them and they are killing performance. These disproportionately affect image models since those models use upsamplingwhich involve indirect indexing.
This update covers two weeks, on account of memorial day holiday, and also most of the dynamic shapes crew was working on FSDP tracing.
PT Core Libraries offsite. PyTorch Core Libraries had an offsite. The big dynamic shapes relevant conversation we had was with @jbschlosser on nested tensor support in PT2. There will be an announce post coming soon about this working E2E; now we need to roll our sleeves up and put it into core PyTorch. One big resolution from our discussion was that it is not necessary to model jagged dimensions in our lowering stack: while having a jagged dimension, e.g., (B, H, W) where height and width can vary, is intuitive for end users, during lowering it is acceptable to lower this as an ordinary 1D dense tensor (BHW,) which contains a bunch of extra metadata that says how to reconstruct the other metadata. This is because our passes like autograd/etc do not care about the jagged structure of the tensor. Additionally, one theme was a lot of PyTorch library developers really liked doing development now in PT2, so there is a lot of interest in improving the “I want to add a new feature to PT, and I will use PT2 so I don’t have to write a CUDA kernel.” Dynamic shapes is pretty essential for kernel writers!
A reach out from FT users. Some folks using FT to do LLM inference are interested in what the long term state of dynamic shapes and PT2 will be; will PT2 be a viable alternative to FT? Today, our gap with FT is moderately significant, esp because we cannot use CUDA graphs with dynamic shapes. However, we hope that (1) with things like kvcache, you do not actually need dynamic shapes and (2) continual improvements to PT2, we will be a competitive and much more user friendly alternative to FT. Hopefully with our increasing focus on LLMs (thanks @drisspg and the rest of the blueberries folks) we should continue to make progress on this front.
RelaxUnspecConstraint some mor - this makes mark_dynamic no longer complain if you mark a 0/1 size dim dynamic (it will specialize, but no big deal)
CI skips. -1, -1, -1, -2 (+1, 0, -1, 0). hf_T5_generate and cm3leon_generate are now passing (though hf_T5_generate in a somewhat hacky way). New failure is nanogpt_generate which was previously failing even in static, new work item for us.
There is a discontinuity in speedup, due to a change in how we count speedup: we now (1) clamp model speeds to 1x (previously, a PT2 caused slowdown could depress overall speedup; this was the case for torchbench was revised from 1.12 to 1.15), and (2) we now include models that fail accuracy in geomean speedup as 1x (this depresses the geomean speedup, e.g., HuggingFace was revised from 1.48 to 1.45).
Metric
Torchbench
Huggingface
TIMM models
Passrate
88%, 56/64
98%, 44/45
100%, 60/60
Speedup
1.15x → 1.16x
1.45x → 1.53x
1.20x → 1.22x
Comptime
79s
100s → 103s
134s → 135s
Memory
0.93x → 0.94x
0.97x → 1.00x
1.01x
Notes:
HuggingFace and torchbench improvements are due to several broad base optimizations that affected all configurations; these include inductor: eliminate meaningless copy and squash xblock for persistent inner reduction (this one disproportionately affects transformer models and accounts for all of the torchbench improvement).
2% TIMM models geomean increase is attributable to a big improvement in lcnet_050. It is not entirely clear which PR booked this win but my guess is the Triton pin update.
There is a huge performance for TIMM models win landed via convolution layout optimization, but it is disabled for dynamic shapes, so we didn’t see any benefit from it.
I probably ought to report inference numbers too but they are only being run twice a week and our latest set of improvements are not in an official benchmark run.
Update on dynamic shapes by default. Voz has handed off this workstream to me. Here is what you need to know:
Staged roll out. Consider three relevant config variables: dynamic_shapes (is dynamic shapes enabled at all), automatic_dynamic_shapes and assume_static_by_default (do we assume everything is static or dynamic by default). Prior to this week, the default settings for these variables were dynamic_shapes = False, automatic_dynamic_shapes = False (updated to this recently), assume_static_by_default = True. Phase 1: dynamic_shapes = True (but note that this should be NO substantive behavior change, since we assume static by default, and don’t automatically promote to dynamic on recompilation.) Phase 2: automatic_dynamic_shapes = True.
State of Phase 1. Our strategy is to incrementally remove all explicit tests on dynamic_shapes in the codebase, at which point switching to dynamic_shapes = True is trivial. This spreadsheet tracks all remaining use sites: Dynamic shapes by default tracker - Google Sheets The biggest cluster of failures involve side effects from allocating a ShapeEnv (even if it is unused); the most complicated failures regard indexing strength reduction and layout optimization in inductor.
State of Phase 2. Voz gamed out what test suite changes would be necessary in https://github.com/pytorch/pytorch/pull/100815 . A lot of the brittleness is from tests that assume that running with different sizes would induce a recompile (which may no longer happen if you hit the symbolic case.) This part is still a bit murky. Hopefully the hardening work we’ve been doing will help make this smooth.
We fixed dynamic=True to not assume static by default. This regressed a while ago and we’ve finally gotten around to reverting the behavior back. If you say torch.compile(dynamic=True) this means “YOLO make everything dynamic.” To only make things dynamic if they actually vary, instead set the configs dynamic_shapes=True; automatic_dynamic_shapes=True (this is no longer controlled by dynamic=True as we intend to make this behavior default).
PT2 internal customers brainstorm. It’s roadmapping season. Dynamic shapes was a recurrent theme for our internal use cases, as dynamic shapes recompilation and jagged tensor are key gaps in our PT2 support. Edward asked to follow up on how comprehensive our per-operator dynamic shapes support is (when do we specialize?) and improve our logging to better identify when recompilation happens. In fact, we already have logs for recompilation, but they are useless because they are attributed to dynamically generated Python code from FX codes; need better provenance.
Model enablement.
lit-llama: I’m slowly working on adding it to torchbench (this is really stress testing our benchmark infrastructure, as some of the reported bugs involve the fine-tuning training recipes which isn’t really something that our current benchmark runner knows how to do. The PoR is to have separate lit_llama, lit_llama_lora, lit_llama_generate). This model triggers a lot of bugs.
Wav2Vec2: This has some sort of AOTAutograd problem, I’m also close to adding it to the huggingface benchmark suite, was blocked on deepcopy not working on the model which is fixed by Add parametrization version of weight_norm
Inference dashboard (as of daf75c0759, comparing with 7c2641d5f1).This week on HUD
Metric
Torchbench
Huggingface
TIMM models
Passrate
85%, 63/74 → 86%, 64/74
100%, 45/45
100%, 60/60
Speedup
1.31x → 1.37x
1.45x → 1.94x
1.36x → 1.43x
Comptime
23s → 27s
36s → 42s
36s → 41s
Memory
1.10x → 1.14x
1.24x → 1.60x
1.16x → 1.06x
This is more like a two week range, because last week the granularity of inference run was very coarse (we are now running inference daily, thanks Bin.)
Passrate is a two steps forward, one step back deal. cm3leon_generate and hf_Bart succeeding; doctr_reco_predictor now failing (this model is failing for all configs, not just dynamic.)
Perf improvement is due to an across the board improvement. Frustratingly, I have no idea which PR the improvement is for! The suspect range is 07104ca99c9d297975270fb58fda786e60b49b38..49450fe021cc5d439f56580463461ff438f9ac96 (which, perhaps not so coincidentally, is the same range that doctr_reco_predictor started failing.) UPDATE: This is because we turned on AMP for inference, whereas previously everything was in float32. Mystery solved! Thanks @eellison
Dynamic and blueberries in the benchmark suite as model sets. A model set (notated with the square brackets) is a subset of models from our existing benchmarks which we are aggregating separately to track something we care about. The Dynamic model set covers models which we expect dynamic shapes support to be relevant. Here is the current list, and some potential threats to validity which need follow up:
// _generate variants are good; they do E2E autoregressive
// generation and will induce varying context length.
cm3leon_generate
nanogpt_generate
hf_T5_generate
nanogpt_generate
// detection models are ok-ish; the good news is they call
// nonzero internally and exercise dynamic shapes that way,
// the bad news is we may not run enough iterations with
// varying data to get varying numbers of bounding boxes.
detectron2_fcos_r_50_fpn
vision_maskrcnn
// this recommendation model internally uses sparse tensors
// but once again its not clear that dynamic shapes is exercised
// on this sparsity
dlrm
// these language models are only running a single next
// word prediction, were NOT testing dynamic sequence length
// performance
llama
BERT_pytorch
hf_T5
// the GNN benchmarks only one run one batch so you
// arent actually triggering dynamism (and we didn't
// explicitly mark something as dynamic)
basic_gnn_edgecnn
basic_gnn_gcn
basic_gnn_gin
basic_gnn_sage
The blueberries set is meant to capture important LLM models, but it is very much a WIP right now.
Dynamic shapes by default. We made a lot of progress. Phase 1 is completely landed in master; Phase 2 has a PR open that is passing all CI tests: Enable automatic_dynamic_shapes by default by ezyang · Pull Request #103623 · pytorch/pytorch · GitHub After discussion with CK/Xiaodong we’re also going to try YOLO’ing internal enablement here too, after I add instrumentation that will help us detect when automatic_dynamic_shapes triggered. I also promised gchanan that I would rename automatic_dynamic_shapes to something more clear, maybe automatic_dynamic_on_recompile. PSA: you probably don’t want dynamic=True, esp if you’re running into bugs; use automatic_dynamic_shapes=True!
How to test for dynamic shapes without dynamic_shapes. So you want to add a new feature to PT2 but it doesn’t work with dynamic shapes. What can you do?
Force specialization when it applies. All backends (e.g., inductor) are permitted to force extra specializations that were not strictly necessary. So if you know that you absolutely want your feature to apply, you can just specialize (e.g., by just int()'ing a SymInt). With dynamic shapes, you may end up with some extra int inputs in your FX graph that are actually static, but these are easy enough to ignore by testing if your input is Tensor or not. This is what we did for CUDA graphs.
Test if there are torch.fx.experimental.symbolic_shapes.free_symbols. If everything is static, then there are no free symbols. This works best if you’re in some local situation where you need to decide to do something to a single tensor, but if you’re doing analysis on an FX graph it’s doable (you just may need to check multiple nodes.) This is what we did for layout optimization.
Don’t apply automatic_dynamic_shapes if we force tensor to be static major automatic dynamic bug fix; we accidentally were making parameters dynamic, which could occur when a module block was instantiated multiple times at different parameter sizes. This was probably the biggest source of failures with automatic dynamic.
Not much to report. torchbench decrease appears to be due to a clear 10% regression on timm_efficientdet. However, it’s unclear how real this regression is because this model has always failed accuracy. timm is within noise.
Inference was swapped to bfloat16 so… we don’t really have any point of comparison historically, because previously we were only running amp. Here’s the snapshot of data on the most recent run.
Metric
Torchbench
Huggingface
TIMM models
Dynamic
Passrate
88%, 63/72
100%, 46/46
100%, 60/60
58%, 7/12
Speedup
1.52x
1.64x
1.72x
1.92x
Comptime
24s
38s
30s
45s
Memory
0.82x
1.15x
1.06x
1.11x
Some thoughts from an apples-to-oranges comparison:
In absolute terms, the torchbench pass rate went down, but there are two models (I cannot easily tell from the display) which were removed from the suite entirely.
PT2 is more beneficial on bfloat16 than AMP, which is expected!
Memory compression is extremely bad. We still need to figure this out.