State of symbolic shapes: Apr 7 edition
Previous update: State of symbolic shapes branch - #48 by ezyang
Executive summary
- T5 is fast now. In T5 model taking too long with torch compile. · Issue #98102 · pytorch/pytorch · GitHub, HuggingFace was trying out torch.compile on an E2E T5 model. Their initial attempt was a 100x slower because their model was dynamic and repeatedly recompiled. After fixing a long string of issues (switch to dynamic=True, patching in their change to exclude compilation time from iter/s calculation, eliminating guards on NN parameters, reducing inductor induced recompilation), we are now 2x faster than eager mode! A great result.
- Dashboard changes. We changed some of the methodology of our performance runs, mostly making it stricter. In particular, we now require sequence length in huggingface to be dynamic (previously, we only marked batch dimensions as dynamic), and we now require batch dimensions to be compiled dynamically (raising an error if the batch dimension gets specialized.) These did not materially affect our pass rates, but enabling dynamic sequence length on huggingface did result in an end-to-end perf regression. We also switched accuracy CI to dynamic batch only, which eliminated most of our outstanding CI failures. One potential methodology problem still in our performance runs is we do not propagate dynamic dimensions; thus, if a model has a graph break, all subsequent graphs will be compiled statically. We need to better understand the extent of this problem.
- mark_static. There is now a mark_static function, which is analogous to
torch._dynamo.mark_dynamic, except that it forces a dimension to be compiled statically. So overall, your tools for controlling dynamism are: dynamic=True makes everything dynamic (but duck sized), mark_static lets you force things to be static, assume_static_by_default makes everything static, and mark_dynamic lets you force things to be dynamic. Once @voz lands automatic dynamic detection on recompilation, we will switch assume_static_by_default to be the default and you can either explicitly mark_dynamic, or wait for a recompile to induce dynamism. Making everything dynamic by default would be relegated to situations where you absolutely do not want to recompile. - Inductor optimization ablation study. Check out A small inductor optimization ablation study for a better understanding of where the performance gaps between dynamic shapes and not are coming from.
- A new strategy for inductor guards. Last week, we proposed that in forwards, we may need to have a notion of an “inductor” graph break, which would permit inductor to install guards on otherwise dynamic values that we cannot float to the top level. While this is still necessary in principle, our new thinking is that we should rarely need it: most guards from inductor arise from optional optimizations, and what we should do is just make sure to disable these optimizations when we cannot conveniently install a guard.
- Guard CSE. Yukio has a PR https://github.com/pytorch/pytorch/pull/98488 for running CSE at a Python-level on guards. It shows a 2-4% across the board performance improvement. Nice! There are some correctness issues that must be ironed out before landing.
- Nested tensor metadata format change proposal. Me, Joel, Alban and Basil worked out an alternate proposal for nested tensor metadata representation, motivated by Joel’s difficulties in modeling nested tensor contiguity with symbolic shapes, as nested tensor stores strides in a tensor, which means there is no straightforward way to actually compute if something is contiguous without something data dependent. The updated proposal has several parts: (1) nested tensor distinguishes dim=0 (the batch dimension) to be the only dimension by which jagged dimensions can vary; in other words, a nested tensor can always be modeled as a list of dense tensors; (2) after the batch dimension, there may be any number of inter-mixed dense/ragged dimensions, followed by a suffix of dense dimensions only; (3) only the suffix of dense dimension and the right-most ragged dimension can be non-contiguous; the batch and inter-mixed dense/ragged prefix MUST be contiguous; (4) this suffix has strides represented as ordinary integers without any raggedness. The general idea is to understand under what circumstances strides can be represented without hitting raggedness, and allow discontiguity on those strides ONLY. Meeting notes at https://docs.google.com/document/d/1BFNKz1XziYbhnBo48kJ9_DzmiwPgcXREpH3La6JCCQU/edit#
- Notable bug fixes.
- Less recompilations (at the cost of disabling certain optimizations): Turn off divisible_by_16 for dynamic shapes, Disable persistent reductions with dynamic shapes
- Reduced guard overhead: Do not track parameters, do not generate guards
- Direct error fixes: Add detect_fake_mode, Teach requires_bwd_pass how to interpret int., Fix some more places where we incorrectly assume only Tensor
- Logging QOL: Only print guard code when printing guards, Add more debug logs to evaluate_expr (you can take advantage of these logs with
TORCH_LOGS=guards,+torch.fx.experimental.symbolic_shapes, definitely useful if you’re investigating overspecialization)
- State of real world model enablement.
- CM3leon-760M (this is that Meta only, name is OK’ed to share) - OK, so it was a roller coaster this week. It turns out that this model wasn’t ever 5x faster; instead, we had missed that the units had changed from ms to s (oof!) Benchmarking with torch.profiler suggested that guard overhead was a major problem, and we shelved it for now. However, work on T5 identified a number of problems; so at the end of the week I gave CM3Leon and we now see a very slight improvement (at generate_size=10, we go from 150ms to 131ms.) Kineto profiles suggest CPU overhead is still an issue (see below), though TBF Kineto always thinks CPU overhead is the problem (due to the fact that the profiler distorts CPU overhead.) One hope is that upcoming attention optimization by jansel should help.

The numbers (as of 46d765c):
- Model status on master.
- CI skips (aot_eager inference/training; inductor inference/training): 0, 0, -1, 0 (+1, +2, +6, +1 WoW); the improvements are primarily due to switching to dynamic batch only (in other words, the bugs still exist, but we expect realistic usage not to care about them as they result from making dimensions dynamic that don’t need to be dynamic)
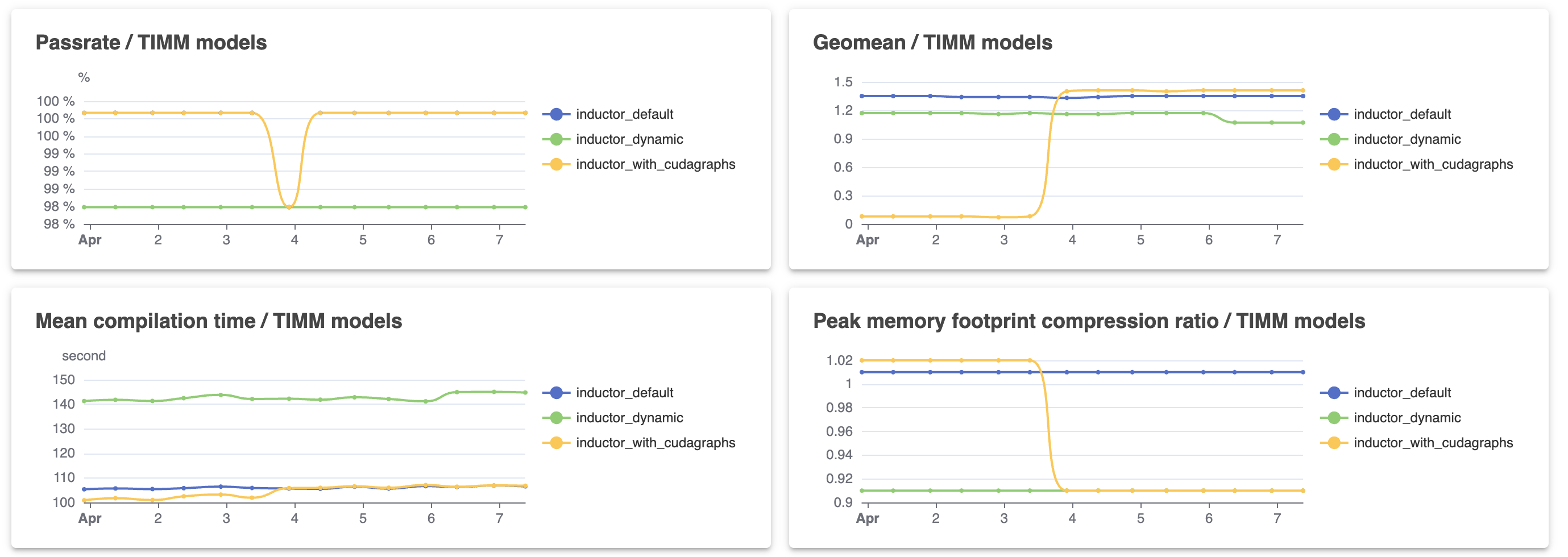
- Perf passrate (torchbench, huggingface, timm_models): 53/63, 43/45, 61/62 (-1, +2, 0 WoW) (delta: -3, -2, -1). vision_maskrcnn
- Geomean speedup: 1.09x, 1.35x, 1.07x (0, +0.07x, -0.10x WoW) (delta: -.06x, -.04x, -.28x). Need to investigate TIMM slow down
- Mean compilation time: 81s, 97s, 145s (-3s, -7s, +4s WoW) (delta: +22s, +35s, +38s)
- Peak memory footprint compression ratio: 0.75x, 0.99x, 0.91x (-.01x, -.04x, 0 WoW) (delta: -.15x, -.02x, -.10x)



What’s coming next?
- Voz: Autodetect dynamic on recompile
- Edward: solidifying specialization logging, fixing CI validity problems, fix backwards soundness problems
- Horace: 1. Dynamic shape minifier, 2. Some shape padding stuff, 3. Pre-autograd make_fx