State of symbolic shapes: Jul 4 edition
Previous update: State of symbolic shapes branch - #58 by ezyang
Executive summary
This is a little more than two week’s worth of updates, covering PSC week, Edward on vacation and July 4th holiday.
- Dynamic shapes by default is landed. To be clear, this is “automatically enable dynamic shapes if recompiling due to size changes.” Most models running PT2 should not see any difference, as they are static already. If your model has dynamism, expect dramatically lower compilation times at the cost of some E2E performance. There may be performance regressions, please file bugs if you encounter any. You can use TORCH_LOGS=dynamic to diagnose if dynamic shapes is doing something. Check also the Meta only post
- Internal telemetry for dynamic shapes. Add signpost_event to dynamic_shapes adds a hook which we use internally to record all uses of dynamic shapes. You can check if dynamic shapes was actually used when
free_symbolsis non-zero. - Notable bug fixes.
- Allow Unequality in top level IR too and Support printing inequality in ExprPrinter - fixes HuggingFace StableDiffusion
- Notable new issues.
- [torch.compile] Guards failures due to storage offsets in new nightly - I believe this was fixed by reverting https://github.com/pytorch/pytorch/pull/104204
CI skips. -3, -1, -1, -2 (no change).
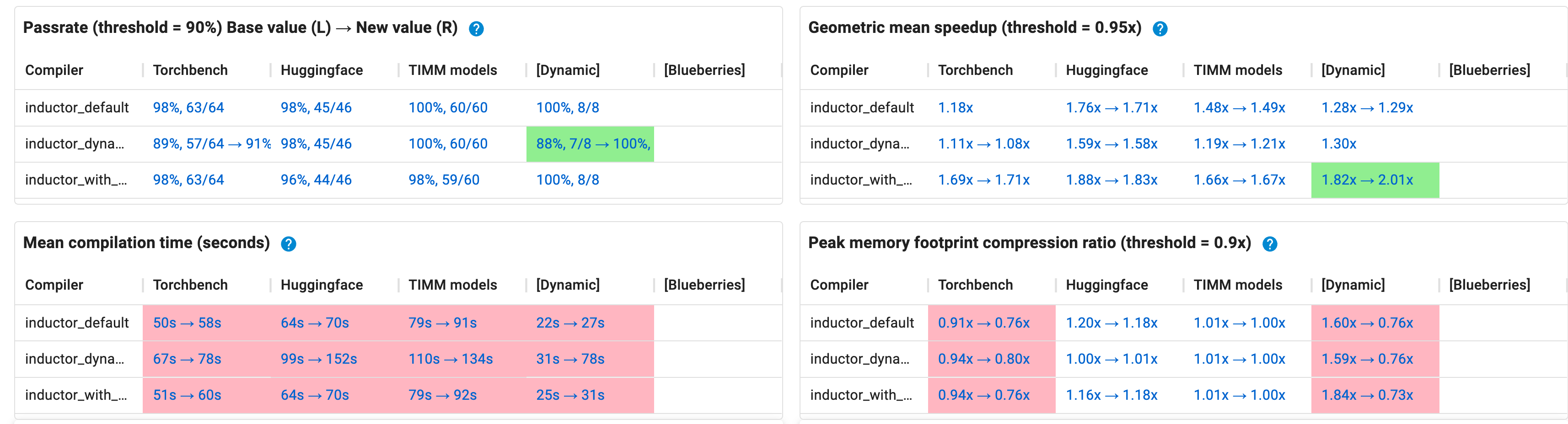
Training dashboard (as of 7ae100628e). This week on HUD
| Metric | Torchbench | Huggingface | TIMM models | Dynamic |
|---|---|---|---|---|
| Passrate | 89%, 57/64 → 91%, 58/64 | 98%, 45/46 | 100%, 60/60 | 88%, 7/8 → 100%, 8/8 |
| Speedup | 1.11x → 1.08x | 1.59x → 1.58x | 1.19x → 1.21x | 1.30x |
| Comptime | 67s → 78s | 99s → 152s | 110s → 134s | 31s → 78s |
| Memory | 0.94x → 0.80x | 1.00x → 1.01x | 1.01x → 1.00x | 1.59x → 0.76x |
- vision_maskrcnn is responsible for the pass rate increase, but it’s fake: accuracy runs pass, but performance runs are still failing. Tracking issue: vision_maskrcnn: AssertionError: expected size 368==368, stride 156==28 at dim=0 · Issue #104653 · pytorch/pytorch · GitHub
- Major HF compilation time regression is due to Re-enable low memory dropout by eellison · Pull Request #103330 · pytorch/pytorch · GitHub which is being reverted
- Memory compression change is due to Add num_elements_per_warp as an triton_config by ipiszy · Pull Request #103702 · pytorch/pytorch · GitHub ; we are discussing how to deal with it, eellison’s position is that the change is “not real” (because it’s just due to an extra 250MB used for Triton autotuning)



Inference dashboard (as of 7b3242d5f7). This week on HUD
| Metric | Torchbench | Huggingface | TIMM models | Dynamic |
|---|---|---|---|---|
| Passrate | 88%, 63/72 → 86%, 63/73 | 100%, 46/46 | 100%, 60/60 | 58%, 7/12 |
| Speedup | 1.52x → 1.53x | 1.64x | 1.72x → 1.73x | 1.92x → 1.96x |
| Comptime | 24s → 28s | 38s → 45s | 30s → 34s | 45s → 53s |
| Memory | 0.82x → 0.67x | 1.15x → 1.11x | 1.06x → 0.84x | 1.11x → 0.86x |
- New model added: DALLE2_pytorch
- Compile time regression on Jun 29 is not entirely clear; maybe it is fix specialization when you pass an unspec int into slicing on a Python list. by cdzhan · Pull Request #104142 · pytorch/pytorch · GitHub



