Highlighting TorchServe’s technical accomplishments in 2022
Authors: Applied AI Team (PyTorch) at Meta & AWS
In Alphabetical Order: Aaqib Ansari, Ankith Gunapal, Geeta Chauhan, Hamid Shojanazeri , Joshua An, Li Ning, Matthias Reso, Mark Saroufim, Naman Nandan, Rohith Nallamaddi
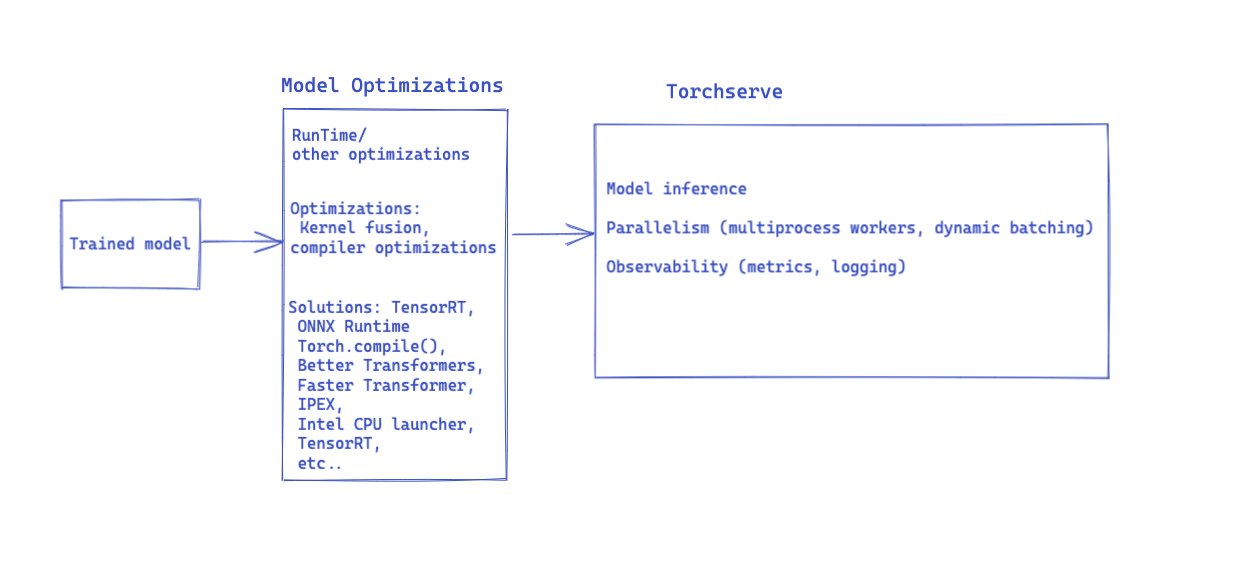
What is TorchServe
Torchserve is an open source framework for model inference, it’s a project that’s co-developed by the Applied AI team at Meta and AWS. Torchserve is today the default way to serve PyTorch models in Sagemaker, Kubeflow, MLflow, Kserve and Vertex AI. TorchServe supports multiple backends and runtimes such as TensorRT, ONNX and its flexible design allows users to add more.
Summary of TorchServe’s technical accomplishments in 2022
Key Features
- A CPU performance case study we did with Intel
- Announcing our new C++ backend at PyTorch conference
- Optimizing dynamic batch inference with AWS for TorchServe on Sagemaker
- Performance optimization features and multi-backend support for Better Transformer, torch.compile, TensorRT, ONNX
- Support for large model inference for HuggingFace and DeepSpeed Mii for models up to 30B parameters
- KServe v2 API support
- Universal Auto Benchmark and Dashboard Tool for model analyzer
Key Customer Wins
- Amazon Ads: Using PyTorch, TorchServe and AWS Inferentia to scale models for ads processing
- Walmart: Search Model Serving using PyTorch & TorchServe
- Meta’s Animated Drawings App: Performance tuning using TorchServe
When we refer to TorchServe as an inference framework, sometimes people ask us questions about how we compete with torch.deploy or torchscript but the inference problem is a bit more general it includes
- Running model.forward() across multiple workers
- Dynamic batching
- Deploying on a large range of surfaces including Docker, K8 and local deployments
- Observability with model and system level tracking
- Inference and Management APIs

These are all components that we’ve ironed out since the inception of TorchServe. We continued to make them more robust in 2022.
When evaluating an inference framework, In addition to supporting the core functionality, we think the following are some important considerations and we focused on all three areas in 2022.
- Inference Speed
- TorchServe’s ability to work at Scale
- Integration of TorchServe with other state of the art libraries, packages & frameworks, both within and outside PyTorch
Inference Speed
Being an inference framework, a core business requirement for customers is the inference speed using TorchServe and how they can get the best performance out of the box. When we talk about Inference speed, this can be divided into 2 parts: Model Speed & Framework speed
Model Speed
Through various experiments, we discovered that it was easy to enable model optimizations when used with TorchServe. Below, we present how we went about supporting various model optimizations with TorchServe.
To deploy a model using TorchServe, the user has to first create a handler file which describes how to init a worker, how to preprocess, do inference and postprocess data. This handler file is just a regular Python script.

Once the handler file and weights are ready then you can package them up and then start torchserve

Because it’s just python and because our users increasingly had demands on model performance, we opted for making all the choices available to users
HuggingFace + Accelerated Transformers integration #2002
TorchServe collaborated with HuggingFace to launch Accelerated Transformers using accelerated Transformer Encoder layers for CPU and GPU.
We have observed the following throughput increase on P4 instances with V100 GPU
- 45.5% increase with batch size 8
- 50.8% increase with batch size 16
- 45.2% increase with batch size 32
- 47.2% increase with batch size 64.
- 17.2% increase with batch size 4.
To get these benefits, we need to set the following in setup_config.json

The example can be found here
torch.compile() support #1960
In December 2022, PyTorch 2.0 was announced in the PyTorch Conference. The central feature in Pytorch 2.0 is a new method of speeding up your model for training and inference called torch.compile(). It is a 100% backward compatible feature to get improved speed-up out of the box.
To make sure of torch.compile(), we just wrap our model with the function as follows, we’ve added some reasonable defaults like mode=”reduce-overhead” which will be ideal for small batch sizes and automatically enable tensor cores for you if you’re using an Ampere GPU.

PyTorch 2.0 supports several compiler backends and customers can pass the backend of their choice in an extra file called compile.json although granted those aren’t as well tested as Inductor and should be reserved for advanced users. To use TorchInductor, we pass the following in compile .json.

There are however some important caveats, dynamic shape supports is still early and because we can’t enable it by default we’ll recompile the model when the batch size changes, this is not ideal especially for torchserve where dynamic batching is a critical feature so as a workaround you can set a large batch delay or a small batch size in your config.properties to guarantee that a batch will almost always be filled out.
ONNX models served via ORT runtime & docs for TensorRT #1857
TorchServe has native support for ONNX models which can be loaded via ORT for both accelerated CPU and GPU inference.
To use ONNX models, we need to do the following
- Export the ONNX model

- Package serialized ONNX weights using model archiver

- Load those weights from
base_handler.py

- Define custom pre and post processing functions to pass in data in the format your ONNX model expects with a custom handler
TensorRT support
TorchServe also supports serialized torchscript models and if you load them in TorchServe the default fuser will be NVfuser. If you’d like to leverage TensorRT you can convert your model to a TensorRT model offline by following instructions from pytorch/tensorrt and your output will be serialized weights that look like just any other serialized PyTorch model.

The TensorRT model can be loaded using torch.jit.load() command similar to a TorchScripted model and hence, from TorchServe’s perspective there is no additional code needed to handle TensorRT models.

lPEX launcher core pinning #1401 .
To get the best performance out of the box from TorchServe on CPU, set cpu_launcher_enable=true and ipex_enable=true in config.properties. This improves performance because of the following
- Launcher distributes cores equally to workers
- Avoids core overlap among workers significantly boosting performance
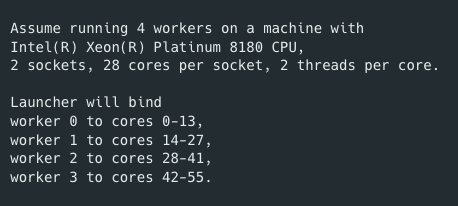
More details can be found here
Universal Auto Benchmark and Dashboard Tool #1442
With just one command, this tool allows users to generate benchmark reports and dashboards on any device with ease.
python benchmarks/auto_benchmark.py -h
usage: auto_benchmark.py [-h] [--input INPUT] [--skip SKIP]
optional arguments:
-h, --help show this help message and exit
--input INPUT benchmark config yaml file path
--skip SKIP true: skip torchserve installation. default: true
As an example, this blog utilizes the tool to analyze the model and optimize its performance. More details can be found here.
Framework Speed
TorchServe is divided into frontend and backend. The former receives the http/grpc calls and performs request batching. The latter calls the handler which ultimately calls the model. While the frontend is written in Java, the current backend is Python based. To maximize performance of the parallel execution of batches each worker runs in its own process.
Therefore, we had two possible ways of optimizing the framework speed during 2022. Optimizing the frontend or adding a new backend. Due to the recent progress with torch::deploy and its ability to run Pytorch models in a thread-based C++ environment we opted for the new backend and provided a C++/TorchScript based backend option to our users. This will have two major benefits. First, it gives users the ability to write their own fast C++ based pre- and post-processing. Second, with a future integration of torch::deploy we will be able to run models in a threaded environment which will allow us to share the CUDA and libtorch runtimes between workers as well as weights between the ML models. Third, this development establishes the foundation for TorchServe to support model sharing and multithreading in the next phase, which will enhance GPU concurrency and minimize GPU memory usage. Fourth, this development paves the way for TorchServe to be embedded in edge devices.
In this multi-half effort we achieved our first milestone by providing a C++ backend based on TorchScript which was announced at Pytorch Conference 2022. The backend is available on github and integrates in an equivalent way to out Python based workers minimizing necessary changes to the frontend. We created examples for two major use-cases, namely NLP and image classification, to get our early adopters started. This was partially made possible by the work of the TorchText team which provided scriptable tokenizers. The combination of the tokenization with the model made the creation of the NLP example a breeze as we did not have to write a separate pre-processing step.

The workers are still process-based but the milestone provides a great foundation for our next move to build thread-based workers in the next half.
Scaling with TorchServe
An important consideration when choosing an inference framework is the ability of the framework to handle peak traffic at scale. Below we present to you two scalable solutions using TorchServe.
Amazon Ads: Using PyTorch , TorchServe and AWS Inferentia to scale models for ads processing
Amazon Ads help companies build their brand and connect with shoppers through ads. To ensure accurate, safe and pleasant shopping experience for the shoppers, the ads must comply with Amazon’s content guidelines. Amazon Ads developed ML tools to help ensure the ads meet the required policies and standards.
Amazon Ads developed Computer Vision and NLP models to automatically flag non-compliant ads. Amazon Ads deployed these models using AWS SageMaker and TorchServe on AWS Inferentia. They were able to reduce the inference latency by 30% and inference costs by 70%.

Source: PyTorch
The above code snippet shows how to use TorchServe’s custom handler for serving a HuggingFace BERT model on a SageMaker endpoint.
More Details can be found here
Walmart : Search model serving using PyTorch and TorchServe
Walmart wanted to improve search relevance using a BERT based model. They wanted a solution with low latency and high throughput.
Since TorchServe provides the flexibility to use multiple executions, Walmart built a highly scalable fast runtime inference solution using TorchServe

Those familiar with TorchServe would relate to the diagram shown above. Walmart made customizations and added capabilities on top of TorchServe.
They extended the SearchBaseHandler to support loading and inference of models trained in ONNX runtime and TorchScript formats.The model inferencing can be performed on CPU or GPU depending on the ONNX runtime package installed within the model serving environment.

Source: Medium
More details can be found here
Animated Drawings : TorchServe Performance Tuning

Source: https://ai.facebook.com/blog/using-ai-to-bring-childrens-drawings-to-life/
Meta released the Animated Drawings App where users could turn their human figure sketches into animations. This uses Detectron2’s Mask-RCNN model, which was fine tuned on sketches and their animations. This case study showed how they used TorchServe for performance tuning and how they were able to serve peak traffic using TorchServe

More details about the CaseStudy can be found here
TorchServe Integrations
A fast, scalable inference framework also needs to support other libraries and frameworks. TorchServe is constantly upgrading existing integrations and adding support for the new state of the art libraries so customers can easily use their favorite solution.
HuggingFace model parallelism integration
TorchServe added an example showing integration of HuggingFace(HF) model parallelism. This example enables model parallel inference on HF GPT2. Details on the example can be found here
TorchRec DLRM Integration
Deep Learning Recommendation Model (DLRM) was developed for building recommendation systems in production environments. Recommendation systems need to work with categorical data. DLRM handles continuous data through MLP and categorical data through an embedding table. TorchRec is Meta’s open source library for recommender systems in Pytorch. More information on TorchRec can be found in the official docs

In this example, we create and archive DLRM into a mar file, which is subsequently registered in a TorchServe Instance. Then we run inference using curl. Sample_data.json represents a sample input of continuous and categorical variables.

TextClassification with Scriptable Tokenizers
TorchScript is a way to serialize and optimize your PyTorch models. A scriptable tokenizer is a special tokenizer which is compatible with TorchScript’s compiler so that it can be jointly serialized with a PyTorch model. When deploying an NLP model it is important to use the same tokenizer during training and inference to achieve the same model accuracy in both phases of the model live cycle. Using a different tokenizer for inference than during training can decrease the model performance(accuracy) significantly. Thus, it can be beneficial to combine the tokenizer together with the model into a single deployment artifact as it reduces the amount of preprocessing code in the handler leading to less synchronization effort between training and inference code bases. This example shows how to combine a text classification model with a scriptable tokenizer into a single artifact and deploy it with TorchServe


KServe V2 Support
In the early part of 2022, TorchServe added support for the migration from KFServing to KServe. You can find more details on KServe V2 here
Parting notes
In short the main thing we’re prioritizing for 2023 will continue to be increasing the performance of the torchserve framework, making sure that pytorch inference performance is best in class and continuing to remove any impediments to our shipping speed so we can unblock and delight our customers