Hi all! Posting a long-overdue note on functionalization: a piece of infra in PyTorch core that’s gotten a lot of attention over the last year, due to the rising importance of compilers in PyTorch.
This will be a pretty long note, so quick table of contents:
-
What is functionalization / why is it important?
-
How does it work?
-
Functionalization: the back story (where did it come from?)
-
Where does functionalization fit into the PT2 stack?
-
case study #1: graph breaks
-
case study #2: TorchScript comparison
-
-
Where else is functionalization used in PyTorch?
-
Mobile
-
LazyTensor/XLA
-
-
What future work is there?
What is functionalization / why is it important?
Functionalization is a piece of infra: it serves to relieve tension between two goals in PyTorch that are at odds with each other:
-
PyTorch is known for being expressive and easy to use. PyTorch has a huge API surface that supports all sorts of aliasing and mutations on tensors.
-
We want to be able to compile PyTorch programs (see the PT2 manifesto). Compilers generally don’t like mutations.
An easy-to-illustrate example would be this PyTorch code:
def f(x):
y = torch.zeros(3, 3)
# Create an interesting (non-contiguous) alias of y's memory
y_slice = y[:, 1]
# mutate the alias, which should also mutate y
y_slice.add_(x)
return y
>>> f(torch.ones(3))
tensor([[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.]])
When we’re compiling, we want to be able to get out a functionally “equivalent” version of the above program, but with no mutations in it!
Why do we not like mutations?
I said “compilers don’t like mutations”, but what are some examples in our stack today where this is important? To name a few:
-
AOT Autograd includes a “min-cut partitioning” optimization (code) - see a great note by Horace. It involves shuffling nodes around between the forward and backward graph to reduce the number of tensors saved for backwards, reducing memory usage, and also runtime in many cases (reading a saved tensor from DRAM can sometimes be slower than recomputing it on the fly in the backward). “Shuffling nodes around between the forward and backward” is not sound, if those nodes involve side effects (mutation), so this partitioning logic requires a functional graph.
-
AOT Autograd runs dead-code-elimination (code), eliminating “unused” nodes in the graph. Removing a dead node from the graph is easy if you know it’s “functional”, but more difficult if you have to worry about removing a node with side effects.
-
Mobile: The mobile export pipeline (WIP) involves capturing a graph and running several optimization passes on it, including dead-code-elimination, and memory planning. Both of these passes are a lot simpler to write if they can assume no mutations.
-
PyTorch/XLA: XLA is a compiler by google, which takes in HLO IR as an input, and can compile it to multiple types of hardware (including TPUs). If you stare at the operator set in HLO, you’ll find no mutable operations! XLA only takes in “functional programs” as inputs to compile.
-
Other PT2 backends. Inductor is the default backend to PT2, and is actually fully capable of handling mutations. As more graph-mode backends try to integrate with PyTorch, they may prefer to be handed a graph that’s entirely functional for them to optimize.
Another way to look at it is: you could imagine a version of PyTorch with no user API’s for mutation or aliasing. But view + mutation ops in the PyTorch surface API are pretty great! They provide two benefits:
-
They’re a type of performance optimization for eager mode, to re-use memory! But… when we have compilers, we’d prefer to leave all of the optimization to the compiler!
-
They let the user express programs with more flexibility. For example, making the user write a snippet of the code above using only functional operators is a pain; writing the mutable version (y[:, 1].add_(1)) is more intuitive.
How does it work?
I think of functionalization as a program-to-program transformation. Given a program/function of PyTorch operators, functionalization will return a new function, that:
-
Has the same semantics as the old function
-
Has no mutations in it
In fact, it’s exposed in this way as an API in functorch:

That’s a pretty good mental model to have, at the API contract level. There are a bunch of different subsystems in PyTorch around graph capture and graph transformations. And the contract that functionalization provides is that you give it a function / fx.GraphModule (potentially with mutations), and it returns an equivalent function without mutations.
The algorithm
In pseudo-code, the algorithm for removing mutations looks something like this:
# Goal: loop through all nodes (op calls) in the program, eliminating mutations
# While preserving program semantics
for node in program:
if is_mutable(node):
# when we encounter a mutable op x.foo_(), replace it with x_updated = x.foo()
x = node.arg
node.op = get_functional_variant(node.op)
# (1) replace all later usages of x with x_updated
x_updated = node.op.output
for use_site in x.later_usage_sites():
use_site.arg = x_updated
# (2) for every alias of x, regenerate it, given the mutation (given x_updated)
for alias in node.arg.aliases():
alias_updated = regenerate_alias(alias, node.arg)
# (3) and replace all later usages of that alias with alias_updated
for use_site in alias.later_usage_sites():
use_site.arg = alias_updated
This doesn’t really explain implementation details - that might be for a future post, but there are some more details in these slides.
Examples: Before & After
So if you’re a compiler operating on a PyTorch program post-functionalization, what should you expect?
Below are a few examples of how functionalization transforms some existing PyTorch programs. One thing to note: functionalization operates at the level of our ATen API. In the below examples, I mapped them back to torch ops in some cases, just to make the transformation clearer.
Example 1: simple case (1 view + mutation)

Example 2: mutate a slice: Advanced indexing on tensors usually desugar into ATen operators like aten.slice and aten.select. Given an updated “slice” of a tensor, and the original base it came from, ATen also has a few operators that represent generating the “updated” base tensor: slice_scatter, select_scatter, etc (docs).

Example 3: multiple outstanding aliases. When we mutate an alias, we need to figure out how to propagate the mutation to all outstanding aliases

Functionalization: the back story (where did it come from?)
Functionalization involved work from many people over the last few years. A quick timeline of events:
The first version of functionalization started its life ~3 years ago, in the PyTorch/XLA project, under Davide Libenzi. As part of bringing up the PyTorch/XLA project, the team needed a way to convert pytorch programs (which can have mutations), into XLA’s HLO IR (which has no mutations). They pioneered the underlying algorithm and wrote a version of functionalization that acts on PyTorch/XLA’s IR, underneath ATen. This came with some long-standing issues, like aliasing relationships in the graph being severed when you call xm.mark_step(), and not all pytorch view ops being supported.
In mid 2021, Ailing Zhang mentioned the idea of making the functionalization logic more generic and moving it into PyTorch core, operating at the ATen level. In late 2021 the first version of that landed.
Around the same time, Richard and Horace were working on composable function transforms in functorch. After some discussion, in early 2022 we decided to add an API to expose functionalize() as a composable transform in functorch (initial PR, docs)
Throughout 2021, the LazyTensorCore project was gaining steam. It also had a backend through TorchScript, which re-used a lot of the functionalization logic in PyTorch/XLA. In early 2022, we updated the LTC TorchScript backend to use the functionalization infra in PyTorch core, fixing a number of aliasing bugs (PR).
The mobile team needed a version of functionalization that not only removes mutations, but also fully removes striding from a program - guaranteeing that all tensors are contiguous / densely packed. We did this by adding a new set of {view}_copy variants of view operators that always return contiguous tensors (which is not the case for arbitrary view ops, like .diagonal()), and adding a version of the functionalize() transform that removes view operators, and replaces them with their *_copy() variants. More details on that later in this note.
Throughout 2022, the infra behind PT2 picked up steam (dynamo, aot_autograd, inductor), and we identified gaps where certain programs with mutations couldn’t be compiled. Originally, dynamo had some logic to remove mutations in basic cases, and fall back to eager in more complicated cases. This worked reasonably well, but had some issues: the pass couldn’t see into and detect any mutations that were introduced in the C++ parts of our codebase (C++ decompositions, backward formulas called in autograd). In mid 2022, we added support for functionalization to run directly as part of AOT Autograd (enabled in aot_autograd, turned on in dynamo).
Where does functionalization fit into the PT2 stack? (Case Study)
Here I’ll cover:
- A bird’s-eye-view look at where functionalization slots into PT2
- A few interesting cases around aliasing and mutation that AOTAutograd needs to handle, that showcase some design decisions in PT2
Here’s a picture of the 10,000 foot view of the PT2 stack, and where functionalization sits in it (sorry the image is a bit small).

You can see that functionalization is a component inside of AOTAutograd. AOTAutograd does a lot of things, but at a high level it takes a messy forward graph of torch ops, containing mutations, autograd logic, tensor subclasses, and all sorts of stuff from the torch API, and sends clean, lower-level ATen graphs of the forward + backward to a compiler.
The actual code that creates “functionalized ATen IR” inside of aot autograd lives here (code pointer 1, code pointer 2). Note that this code is still under pretty active development.
One important thing to note is that we don’t actually materialize a separate graph for “ATen IR”, “Functionalized ATen”, and “Functionalized ATen + decomps”. We trace directly from “Torch IR” to “Functionalized ATen + decomps” all in one go.
How does AOT Autograd use functionalization? There a bunch of interesting edge cases around how AOTAutograd needs to handle external mutations and aliasing in this doc on AOTAutograd 2.0.
I want to cover two particularly interesting end-to-end cases.
Case study 1: graph breaks + input mutations
An interesting example to look at the interaction between PT2 and functionalization is: what happens if our user code involves mutations and graph breaks? We’ll use this example:

If you run this code, you’ll find dynamo prints two graphs:

But there’s a problem: In graph 2, “y” is a graph input, and it gets mutated. Graph 2 is stateful: running it causes an observable side-effect .
This particular case is a bit unfortunate:
- from the user’s perspective, “y” is a temporary created inside of the function, and the mutation could easily be removed.
- from the compiler’s perspective, we have no idea what “y” is. It could be a piece of global state in the program that needs to be mutated (e.g. a module parameter). After compiling and executing the graph corresponding to graph 2, we are obligated to make sure that any side effects are preserved properly (any graph inputs that got mutated should be mutated).
Does this happen in real user code?
So… does this happen in real models? This example isn’t too contrived - it’s shown up in a number of models in the torchbench suite. For example, you’ll encounter it if you run hf_Longformer:
python benchmarks/dynamo/torchbench.py --accuracy --backend aot_eager --training --only hf_Longformer
The code for that model lives in a HuggingFace repo. That model creates a fresh tensor of zeros, “diagonal_attention_scores” here, with a call to new_zeros(). A few lines further down, it tries to mutate a few slices of “diagonal_attention_scores” here.
The problem is that the call to new_zeros() causes a graph break, so “diagonal_attention_scores” becomes a graph input in the next graph. Why?
- One of the size arguments to
new_zeros()is “chunk_count” - “chunk_count” was created with a call to
torch.div(int, int)here torch.div(int, int)always returns a tensor (a zero-dim tensor in this case).- When we pass a tensor with dim 0 in as a size argument to new_zeros(),
.item()is implicitly called on that tensor. - In general, calling
.item()on a tensor induces a graph break. The idea is that we don’t know the values of data inside of the tensor at compile time, and we need to know the concrete value in order to have compile-time-information on the size of the tensor we’re creating.
Note that in this particular example, the graph break is entirely avoidable. We can beef up our tracing infra to handle torch.div(int, int), and treat its output as being known at compile time. Alternatively, someone could update that user code to perform regular python division on the integers, instead of using torch.div.
Note that In general, PT2 operates in a world where graph breaks can happen for any number of reasons - so even if we fixed this particular model, there will plenty of other cases where we end up in this situation: a graph break can promote an “intermediate mutation” in user code into an arbitrary “input mutation” in a subgraph.
FWIW, another case where input mutations will be common in the near future is optimizers: When we compile the optimizer step, the parameters will (usually) be graph inputs that we update based on the gradients.
How AOT Autograd handles input mutations
As stated above, the second graph has input mutations that we need to respect when we compile the graph. Input mutation support in AOT Autograd landed a few months ago.
AOT Autograd is obligated to create a graph without mutations to optimize, and it’s also obligated to ensure that input mutations are respected. It does this in two steps:
- It creates a graph, with all mutations removed (including input mutations). This is pretty simple - we run functionalization. Functionalization will happily remove all mutations, including input mutations, from a graph.
- it creates a run-time “epilogue” (code), that runs the compiled graph, and performs any input mutations afterwards before returning to dynamo.
In the example above, AOTAutograd will take graph 2 from above and create something like this:
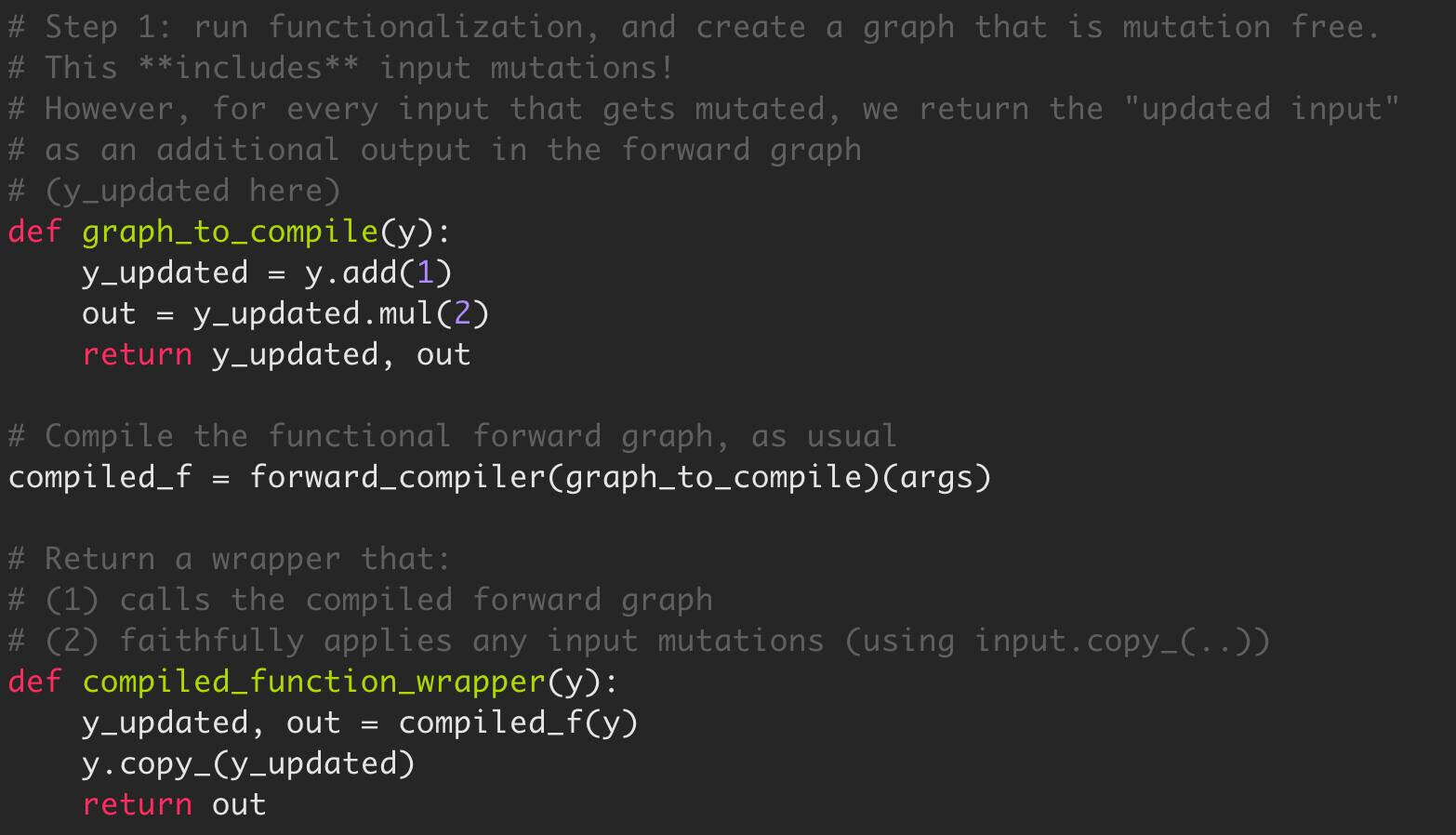
This accomplishes our goal: creating a functional graph to be compiled, and faithfully replicated any observably side-effects from the graph (input mutations), although you might argue it’s not optimal. A future piece of work could be to create a contract with the backend compiler where we agree to send the input mutation into the graph, so the compiler can fuse it.
Case Study 2: specializing on aliasing relationships (and comparison to TorchScript)
Another interesting example is this piece of code:

What’s going on here? Our function mutates x, and then does something with y. This program will have different behavior, depending on whether or not x and y are aliased!
The reason this example is interesting is because it shows a philosophical difference in how PT2 decides to compiles programs, versus say, TorchScript. In particular, guarding + specializing .
How will TorchScript (torch.jit.script) and PT2 (torch.compile) differ in the way that they compile this program?
- TorchScript will compile the above function once . This is useful, e.g. for export, where you have a single, faithful representation of your program. However, it prevents a lot of opportunity for optimization. TorchScript can’t make any assumptions above whether or not x and y alias! That means that TorchScript won’t be able to remove the mutation on x, preventing optimization opportunities.
- PT2 will specialize on the aliasing properties of the particular inputs. For a given set of user inputs, we know whether or not they alias, and we will trace out a different graph to send to the compiler.
- Downside: we might compile more than once (if the user happens to call their function multiple times, on inputs with different aliasing properties).
- Upside: By knowing find-grained aliasing info about our inputs, we are guaranteed to be able to remove all mutations from every program we trace. This means that we can always run all of our optimizations.
The two forward graphs that AOT Autograd will send to our backward compiler in the two cases above look like this:

In the graph on the right, AOT Autograd ends up creating a graph where:
- There is only 1 input, primals_1, corresponding to a synthetic “base” that both x and y are aliases of.
- x and y (the original user inputs) are aliases that are generated off of primals_1, using as_strided. FWIW, the reason that as_strided() is in the graph instead of a simple view() operation is because we’re relying on autograd’s view-replay logic, which defaults to using as_strided() in eager mode. This is something we could consider changing, but would have a negative impact on eager performance. It’s also worth pointing out that this specific alias + mutation case should come up pretty infrequently in user code
- The input args to the
mul.Tensornode are “as_strided_3” and “as_strided_8”; these correspond to “x_updated” and “y_updated”, after “x” was mutated in the user code.
And that’s it! PT2 effectively specializes on the aliasing relationships of its inputs when created a graph, allowing it to optimize more aggressively.
FWIW, the example as written above is actually partially broken: AOT Autograd still needs to be taught how to propagate guards on the aliasing relationships back to dynamo so that it knows to recompile. Instead, as of 1/4/23 the above code will raise an assert failure on the second call.
Where else is functionalization used in PyTorch?
I mentioned that functionalization is used in other areas of PyTorch, aside from PT2. Two other major areas include:
Mobile
Mobile also has another requirement: all tensors in the exported graph must be contiguous (memory-dense) . I won’t go into too much detail here, as mobile folks have written about this previously (see post).
But how can functionalization help here? Functionalization also has another dial for eliminating views. If every input tensors is contiguous, and we have no views in the graph, then we can guarantee that every intermediate and output is contiguous too. Quick example:
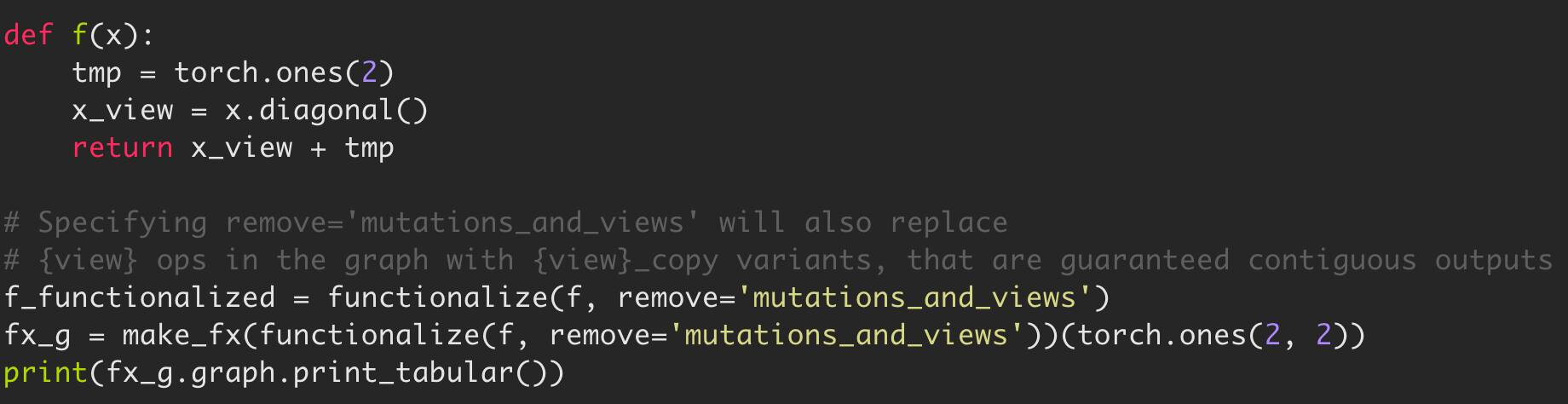
The above prints:

The semantics of diagonal_copy() are that it always returns a contiguous tensor; so the original program and the traced one have the same semantics, but all tensors in the traced program are guaranteed contiguous.
PyTorch/XLA
PyTorch/XLA is working on migrating to use the version of functionalization from in core. There’s a prototype in the works here. When we migrated the LazyTensor TorchScript backend to usef functionalization, that served as a nice blueprint for XLA to use for integration.
Now that functionalization is pretty battle tested, updating PyTorch/XLA to use it will fix a number of known bugs: one is that the mark_step() API currently severs the aliasing relationship between aliased tensors, which can lead to silent correctness issues.
What Future Work Is There?
Future work includes:
- The AOT Autograd 2.0 doc covers a bunch of edge cases around aliasing and mutation; some of these have been fixed, but not all of them are complete (There are outstanding github issues for these bugs, linked in the doc).
- Today, AOT Autograd only actually runs functionalization when it needs to trace a backward, and skips functionalized when only compiling a forward graph. This is sort of ok for now, because we don’t run optimization like min-cut partitioning and DCE in that case, and inductor can handle mutations, but other backends cannot handle mutations, and expect a functional graph (see issue).
- Custom dispatcher ops. “functional” custom ops today with functionalization (any aliasing/mutation that is internal to the op is also ok), but we currently don’t support custom operators that have externally visible alias/mutation semantics (that mutate inputs, or return outputs that alias inputs).
- cond op: the cond() op is needed in the export use case, when we don’t want to specialize on control flow. Tugsbayasgalan (Tugsuu) Manlaibaatar recently added functionalization support for it that covers most cases: if there is internal aliasing/mutation inside of the true/false branches, they will get functionalized. Eventually, we might need to support true/false branches that mutate inputs, and/or alias outputs, similar to the custom op story.
- Compiling through tensor subclasses. This is only tangentially related, but we want a version of AOTDispatch that’s works on tensor subclasses, converting a user program with tensor subclasses into a flat graph of aten ops, that only involves plain tensors. As part of that work, we need to arrange for functionalization to run “underneath” the tensor subclass.
- Improved perf for input mutations. I noted above that when we see input mutations in AOT Autograd, we could theoretically improve perf by allowing the compiler to “see” the input mutation and fuse it in their graph. We don’t do this today, but it’s probably worth benchmarking before committing to this optimization (which might be useful for compiling optimizers)
- XLA. The Pytorch/XLA team has been working on migrating to use functionalization from core.
Thanks!
There are a ton of people to thank, so I’m definitely going to miss some people. That said:
Thanks @ezyang for countless reviews, design discussions, and useful insights around functionalization over the last year
Thanks @zou3519, @Chillee, @albanD, @gchanan, @samdow, @bhosmer for the many discussions around functionalization and how it should fit interact with both AOT Autograd and functorch
Thanks @anijain2305 for help with integrating functionalization with dynamo + PT2
Thanks @larryliu0820, Martin Yuan, @tugsbayasgalan and others from the mobile team for working to think through how aliasing should work in the export case, and integrating functionalization into Executorch.
Thanks Will Constable, Nick Korovaiko + other LTC folks for help thinking through how to integrate functionalization with LazyTensor
Thanks to Jack Cao, Jiewen Tan, Wonjoo Lee and the the external folks from PyTorch/XLA (+ Ailing Zhang) for the initial version of functionalization, that much of this work was based on.