A new strategy for automatic custom operators functionalization that enables re-inplacing on view tensors.
with @zou3519
TLDR We shipped a new auto functionalization strategy for custom operators that automatically and efficiently handles mutatble custom operators (including ones that mutate views). This unblocked the vLLM integration with torch.compile by fixing OOMs with custom KV-cache operators used in LLMs, which we started seeing a lot of in the past year. We enabled this new auto_functionalized_v2 strategy for torch.compile but not yet for torch.export.
For the most part, this is a technical note that explains the new custom op functionalization strategy.
Summary
The torch.compile stack requires functionalization of all operators (built-in and custom) so that it can create a functional IR. This functional IR makes it easy for us to run optimization passes, like identifying fusion opportunities and reordering operations.
Today, we automatically handle the functionalization of mutable custom operators by creating a functional variant of it. The functional variant of the operator runs the mutable variant, but with additional copies. After we have run most optimization passes, a de-functionalizing (re-inplacing) pass reverts the effect of functionalization and removes the introduced copies.
Previously, the auto functionalization strategy (auto_functionalized_v1) did not support re-inplacing custom operators that mutate inputs that are views. We introduced auto_functionalized_v2 to do that; read on for the technical details.
The Details
This rest of the note dives into the details of auto functionalization. The starts by explaining how auto_functionalize (v1) works, its limitations with respect to views, and finally how auto_funcitonalize(v2) mitigates it. This is note by Brian Hirsh is a good intro to functionalization that may provide more context.
Auto_functionalize (v1)
auto_functionalized is a higher-order operator (HOP) that is used to generate the “functional” version of a mutable custom operator. In the program below, foo is a custom op that mutates its input.

After running functionalization we get the following functional program:

The call to foo is wrapped inside auto_functionalized which is a HOP that wraps custom operators and converts it into a functional construct. The semantics of auto_functionalized are the following:
-
Copies all the mutable inputs (node full in the graph above)
-
Calls the custom op foo passing the copies of the mutable inputs.
-
Returns the output of foo, followed by each of the copies of the mutable inputs.
We also have to replace all usages of the mutable inputs with auto_functionalized output (return f in this case is replaced with return getitem1).
To visualize that, we can print the post-grad graph while manually disabling re-inplacing and notice the following; (1) the call to clone the mutable input, (2) the return of the function being the copied input after it is mutated. (do not get confused by as_strided nodes, they are just aliases here).

After all post-grad passes run on the functional graph, a re-inplace pass runs to reverse the functionalization. The algorithm for re-replacing is simple, for each mutable input to the auto_functionalized custom operator:
if the input in the functional graph is not read after auto_functionalized then it can be re-inplaced by doing the following:
-
Do not generate the copy of input (full in the graph above) and pass the input itself to foo during auto_functionalized decomposition.
-
Replace every usage of the copy of the inputs, which is the output of auto_functionalize (getItem1 in the example above) back to the input itself (full in the graph above).
Running the re-inplacing pass in our example yields the following final outputs. foo is called with the original input directly, and there are no unnecessary clones.

Auto_functionalize (v1) and views
Consider the following small alteration to the previous program, where we pass f[0] instead of f to foo:

After functionalization we get the following forward graph.

Note the select_scatter. This is an operation that creates a copy of full and writes the portion of select_scatter[0] from get_item. Since the original program returns f and the portion f[0] was mutated by foo, we need to return a copy of f, that observes the effect of foo on f[0], and the mutation is observed from get_item.
The select_scatter interferes with re-inplacing! The problem is in the re-inplacing part, the criteria for re-inplacing is :"if the input in the functional graph is not read after auto_functionalized then it can be re-inplaced"
It’s tricky to say yes to this question with the existence of select_scatter in the graph, and with the fact that select (the input to foo) is a view. The select scatters takes full as argument? but full share storage with select, does that mean that we read select?
We know the answer for this case but in general this is a hard question to answer and requires an alias analysis. The view operations before auto_functionalize and the scatter operations after can get really messy and complicated !
Due to that complexity, auto_functionalized does not try to re-inplace view operations, giving us the following graph with additional clones:

Auto_functionalize (v2)
We experimented with several designs until we settled on this one.
The main question is the following: is it possible to do the functionalization in a way that avoids dealing with views and scatters so we do not need to worry about the aliasing complexity.
The answer is yes, and the key to the new approach is reformulating inplace-on-view as an in-place on the base tensor followed by the reconstruction of said views. Under this scheme, auto_functionalized_v2’s strategy is that it clones the bases, and mutates those clones, and then the rest of the program reconstructs the views from these mutated clones.
What this does is that it removes the two complexities (view generations before auto_functionalize is called, and select scatter after it is called) so we do not need to worry about any alias analysis.
Here’s an example to demonstrate what we mean. Below is the functional graph that we get when auto_functionalized (v2) is enabled**.**

auto_functionalized_v2 takes the following arguments:
-
all_bases, a list of unique bases of all mutable inputs of the custom operator. In this case, the base of
full[0]is thefullnode. -
For each mutable input _x_bases_index, which identify the index base of x in all_bases
-
ViewInfo Some metadata that tells how to regenerate the view from the base for each arg if its a view, in the case bellow _x_size, _x_stride and _x_storage_offset indicates that we can generate x by calling
all_bases[0].as_strided((), (), 0).
auto_functionalized_v2 have the following semantics:
-
Copy all the tensors in all_bases!
-
Regenerate all the views (if any from all_bases) and pass the new copies (or views) to the custom operator (foo in this case).
-
Returns the output of custom-op followed by the copies of all_bases.
-
We have to replace every usage of any base, after foo is called with the new copy. (This will not generate select_scatters since every variable is either the base itself or a view on top of the new output base).
If we were to decompose auto_functionalized_v2 (without re-inplacing), here’s what it would look like.
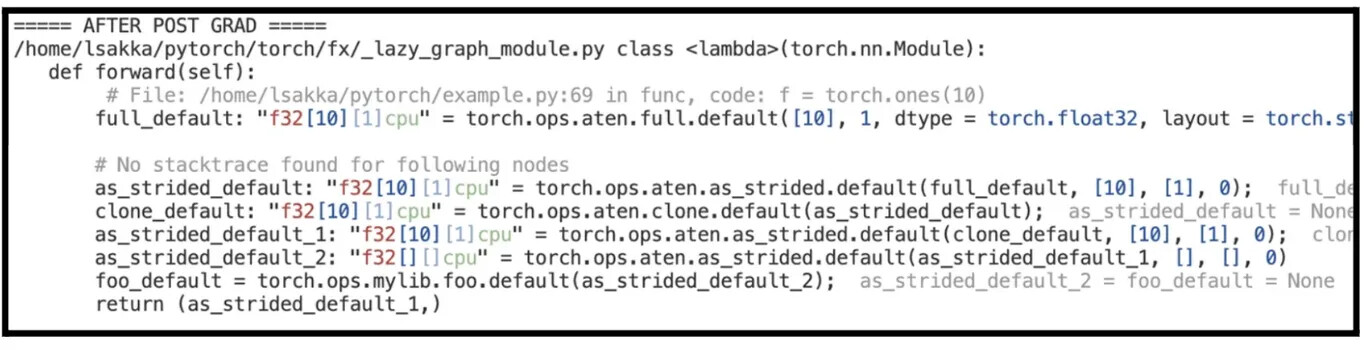
so many as_strided nodes in the code above, but do not get confused they are all aliases except for as_strided_default_2 node!!
as_strided_default_2 is generated when auto_functionalized_v2 is decomposed using the information serialized in the auto_functionalize_v2 call, it generates a view on top of clone_default[0].
Cool Cool , so now let’s check re-inplacing.
We use the same criteria as auto_functionalized(_v1), but apply it to all_bases instead “if the base in the functional graph is not read after auto_functionalized_v2 then it can be re-inplaced*”* . Applying it to full on the forward graph above, the answer is clear: full is not read past auto_functionalized_v2 and we can re-inplace it!!
Inductor is able to re-inplace auto_functionalized_v2 to create a copy/clone-free graph.

Other Interesting stuff :
1. Tracking base in inference mode:
In inference mode, tensors are not aware of their base, so we did some hacking to track the base of tensors by analyzing the shared storages during functionalization.
2. Do we always use as_strided to regenerate the views?
as_strided is very generic and can be used to generate any view; however, Elias Ellison noted that it can potentially cause performance issues in the inductor and is harder to analyze by passes. (it’s harder to reason about what it access). To mitigate that we attempt to infer 4 types of views from the striding information (slice, alias, subscript(not yet implemented) and fall back to calling as_strided if we cannot do the inference.
Future Work
Export mode: auto_functionalized_v2 is not enabled in torch.export; we didn’t find motivating use cases for it. Note that some exported models already serialize an auto_functionalized_v1 HOP, so even if we introduced auto_functionalized_v2, we cannot immediately delete auto_functionalized_v1.
Triton kernel re-inplacing does not go through v2: This may be important; we’re working on logging how impactful this is.