as I am using torch as a backend for a simulation that relies heavily on solving non-hermetian eigenvalue problems I have stumbeled across the quite slow Magma geev implementation.
In the process of troubleshooting I have come across this https://docs.nvidia.com/cuda/cusolver/. It seems that as of this year Nvidia has implemented a native geev implementation into the CuSovler library.
As I have seen a major performance uplift from using this (for a 4000x4000 double matrix >2x on RTX 4070). Also the performance seems to not be limited by the CPU anymore, but rather the GPU, which makes me hopefull for it to actually scale with more powerful GPUs. So I think it would be very beneficial to use this as a new backend in torch.
Now if I understand this right I would need to basically add the call to the new geev function (in the CUDASolver.cpp) and tell torch to use it in the /main/aten/src/ATen/native/cuda part. I do have some (limited) experience writing C++, but just not in such a large project. But as most of the code should be reusable from the hermetian solver and there is an example published by nvida (and I managed to already get my torch compiled form source) I actually feel encouraged to try to do this. Is there anything I am missing in order to get this working, maybe especially the backwards call? (Or should I abandon trying to do this as a noob?)
I’m happy to help provide guidance if you need as well.
For the geev part itself, you should be able to re-use the backward as-is as long as you don’t change the signature in native_functions.yaml.
cc @Lezcano in case you have any concern related to moving to cusolver here
cc @malfet these might be interesting numbers to justify the broader migration away from magma that we were discussing since cuSolver is already a dependency.
Thank you for the answer! I am currently trying to just make some dummy functions to check if I am directing the linalg.eig calls the right way. I got my code to compile fine using Windows with the Visual Studio C++ compiler. The compile and install runs fine, but whenever I try to import torch into Python, I get this issue https://github.com/pytorch/pytorch/issues/157128
So I thought: Well, I will just skip the compiling on Windows issues and move to WSL. That fails for other reasons, though. Torch does not even manage to compile. I set up everything as recommended, but the Ubuntu WSL I am using just completely crashes at some point of the compilation. I think it is right at the point when nvcc starts to compile the first cuda files. There is no error message, nothing.
Now the question I am having is: should I just skip the entire hassle of trying to develop on Windows and move straight to a Linux machine, or is this just something it might be worth troubleshooting? If everyone is just doing the development on Linux anyway, I think I would just move there too.
I have stumbled across a kind of weird thing, maybe someone with more experience with the compile flags in torch can provide some insight:
In CUDASolver.cpp I have found the USE_CUSOLVER_64_BIT flag. As the new XGEEV interface is a 64-bit CuSolver API, I wanted to reuse the flag. The thing ist just: The flag is not used anywhere else. I tried finding it with grep, but it is only in these files and nowhere else, not in any CMake file or anything. When trying to set it via an environment variable, it did not reach my code at compile time.
#ifdef USE_CUSOLVER_64_BIT
# pragma message("USE_CUSOLVER_64_BIT is defined")
#else
# pragma message("USE_CUSOLVER_64_BIT is NOT defined")
#endif
This is what I used in order to check if I actually get the flag, and I always get the NOT defined.
What I did now is edit cuda.cmake to include:
# --- Custom: force 64-bit cuSOLVER API
if(DEFINED USE_CUSOLVER_64_BIT AND USE_CUSOLVER_64_BIT)
message(STATUS "Using 64-bit cuSOLVER API (USE_CUSOLVER_64_BIT=ON)")
add_compile_definitions(USE_CUSOLVER_64_BIT=1)
list(APPEND CUDA_NVCC_FLAGS "-DUSE_CUSOLVER_64_BIT=1")
endif()
This is probably not the right way to do it, and I don’t understand why the build system does not seem to automaticaly configure this flag. Also, my build system does not seem to recognize when CLion changes my files, but I just force ninja to rebuild my files by deleting the .o file associated to it.
I wanted to give a short update:
I have managed to get the cuSOLVER Xgeev path working!
At the moment, I’ve only implemented the eigenvalue computation. The reconstruction of the eigenvectors from the LAPACK-style output is still missing, but that shouldn’t be too complicated. MAGMA adheres to the same format, so this will likely be a matter of adapting that logic.
One thing I noticed is that there are already some assumptions in aten/src/ATen/native/BatchLinearAlgebra.cpp about which backend is used and where the output tensors are allocated. I don’t think these assumptions really apply anymore, since the actual backend decision now happens in linalg_eig_kernel (aten/src/ATen/native/cuda/linalg/BatchLinearAlgebra.cpp`). What are your thoughts on this? Should the device placement logic be moved or refactored accordingly?
Regarding the flag I mentioned earlier:
It seems that it’s just defined in CUDASolver.h. For now, I’ve chosen to keep using it and simply expand the existing #ifdef USE_CUSOLVER_64_BIT block, adding new checks directly against the cuSOLVER version.
That said, I do think this approach might become hard to maintain over time. NVIDIA will likely continue to add more LAPACK-level functionality to cuSOLVER. I’m also not entirely sure that all the existing checks in the linear algebra backend are still relevant in this new setup, so it might be worth rethinking how these backend decisions are handled in the future.
Feedback or thoughts on how to best handle the backend dispatch and version checks would be very welcome!
Hello everyone!
I actually have some good news: CuSolver xgeev is working in my torch and I am just preparing the PR now. There are some problems with testing. I will discuss them in a dedicated topic on this forum.
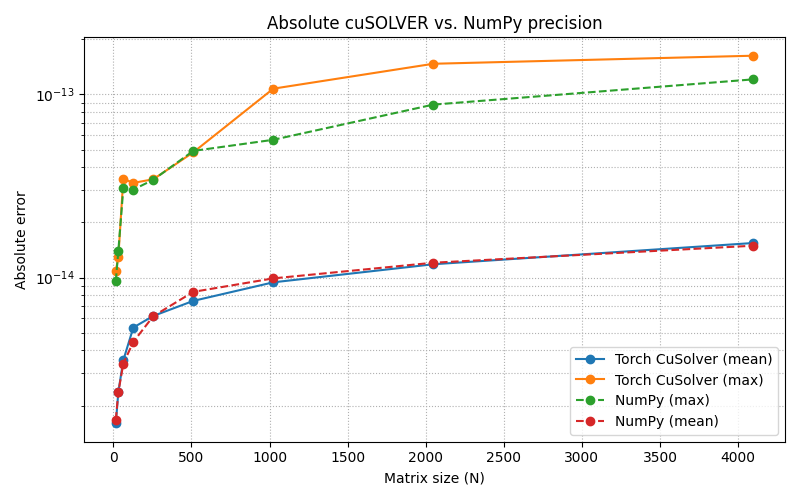
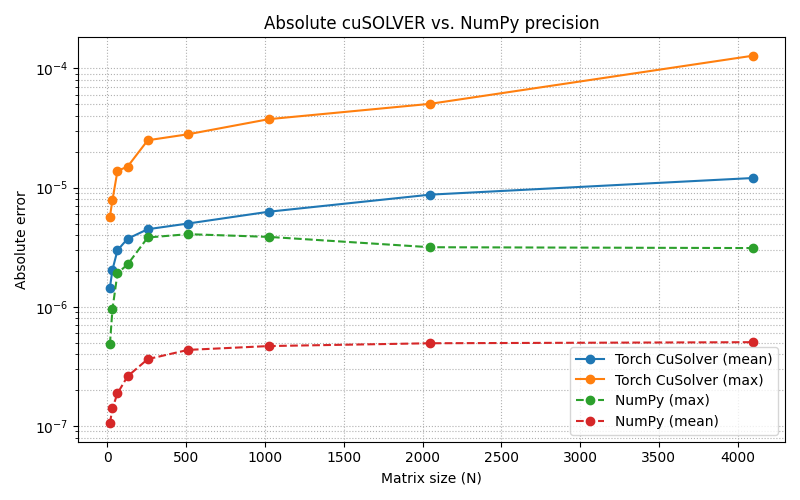
In the meantime, I did some testing regarding the precision of the xgeev algorithm using the eigenvalue equation. So the eigenvalues are defined by saying l * v - A * v = 0. What I did now is evaluate how large the left-hand side of that equation is for the tried and tested NumPy eig implementation and my new algorithm. What I found is that the double precision versions are pretty close (float64 and complex128), but the single precision version of the algorithm seems to be about one to two orders of magnitude worse than NumPy for the matrix sizes I tested.
I hope this will provide some room for discussions in regards to my pull request and also possibly for evaluating torch’s future behavior when choosing backends.
Kind regards, and as always, happy to receive any input.
as I am getting ready to submit the PR, I wanted to share some performance numbers, and they are better than I anticipated. For 32bit precision, CuSolver seems to be 4-5x faster than MAGMA, for 64bit about 2x. This was tested on an RTX4070 and a Ryzen 5700x with Ubuntu and CUDA 12.8. I am trying to get some tests on a H100 and A100, but this might take a while.
For all the numbers shown here, I have always submitted batches of 10 matrices (which aten loops over, there is no real batching in xgeev yet) and averaged the times over 5 runs of the appropriate matrix types and sizes.
It seems that the CPU path is still faster for small matrices (<256). So it might be worth discussing if it is desirable to keep the automatic switch to CPU. As of now, I removed the automatic CPU path for small matrices, as I think it is a little cleaner, and cuSolver is faster way earlier than MAGMA.
Thanks a lot for all the care to details and making sure the numerics are acceptable.
We can definitely move forward with this, I would recommend taking a look at The Ultimate Guide to PyTorch Contributions · pytorch/pytorch Wiki · GitHub for any general question about sending PRs and generally contributions.
Feel free to tag me in the PR and we can also follow up on slack if a higher bandwidth discussion is needed!
4x faster for fp32 and 1.3x faster for fp64 on RTX4070.
A100: 5x faster for fp32 and 7x faster for fp64
H100: 10x faster for fp32 and 15x faster for fp64, crushing my best expectations.
(Speedups compared to the MAGMA CUDA backend, tested with complex64 for the fp32 numbers, complex128 for fp64, n=4096)