For the following case, the fx graph obtained by the inductor entry no longer contains the slice op. Does anyone know where this part is optimized?
e.g. slice ut case
import torch
class NaiveModel(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, arg0_1):
slice_1 = torch.ops.aten.slice.Tensor(arg0_1, 0, 0, 9223372036854775807)
return slice_1
model = NaiveModel()
opt_mod = torch.compile(model, backend="inductor")
x0 = torch.rand(256, 256)
golden = model(x0)
outs = opt_mod(x0)
stage1. pdb in inductor_compile_fx_inner
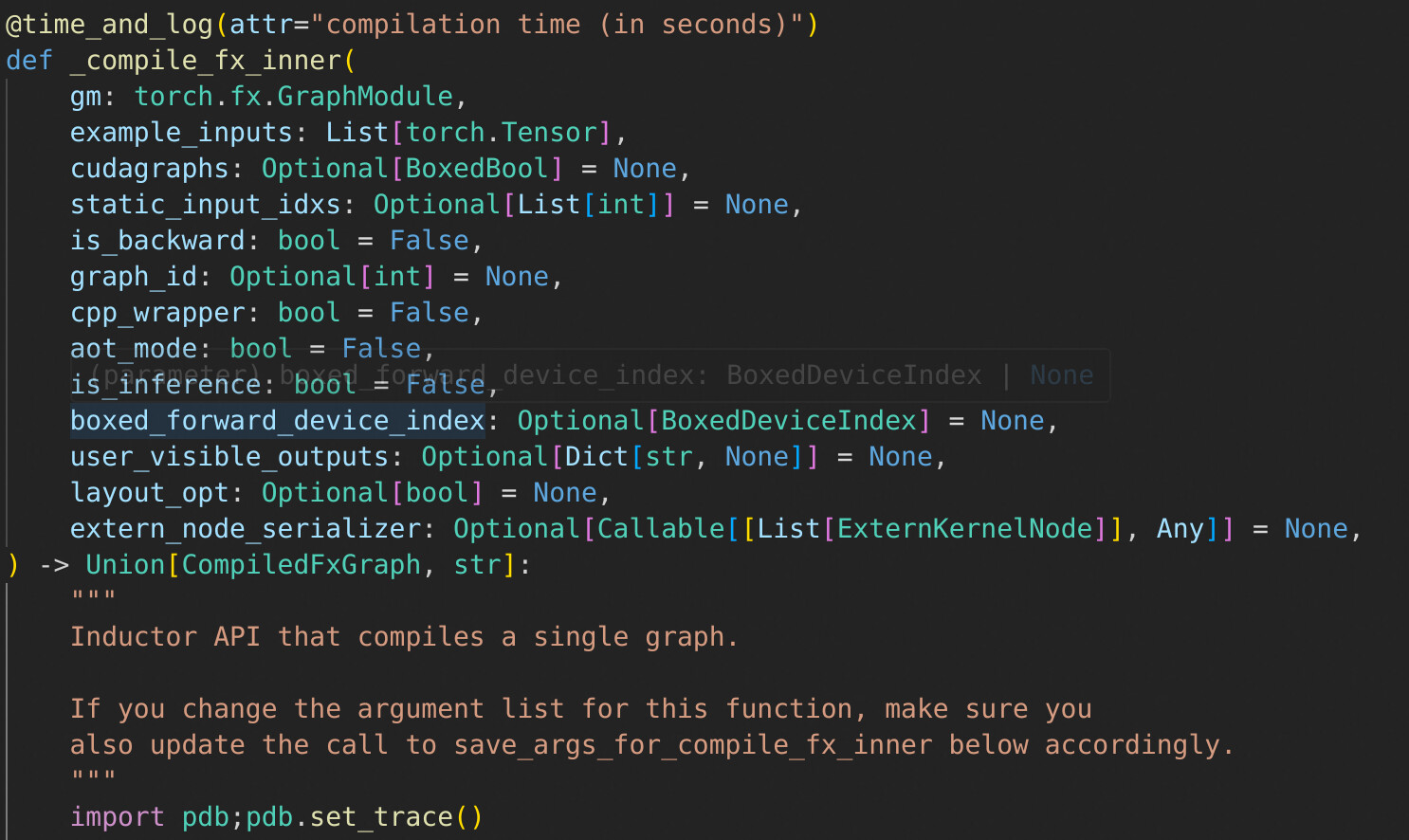
stage2. print(gm.code)
