PyTorch SymmetricMemory: Harnessing NVLink Programmability with Ease
with Horace He, Luca Wehrstedt
TL;DR
We introduced SymmetricMemory in PyTorch to enable users to harness NVLink programmability with ease. SymmetricMemory allows people to easily perform copy engine-based P2P copy with tensor1.copy_(tensor2) and write custom NVLink/NVLS collectives or fused compute/communication kernels in CUDA or Triton.
Background
As distributed parallelization techniques rapidly evolve, we’ve been observing a trend where NVLink bandwidth is being harnessed in an increasingly explicit fashion. Initially, in 1D parallelisms, the NVLink bandwidth is exclusively utilized by NCCL’s rail-optimized PxN collectives. Later, with 2+D parallelisms, practitioners began explicitly allocating NVLink bandwidth to specific traffic (e.g., tensor parallelism). Then, innovative block-wise compute/computation overlapping techniques started to use copy-engine to drive the P2P traffic in order to minimize contention. Now, we are seeing techniques where NVLink communication is directly issued from “compute” kernels.
We believe this trend is driven by a growing awareness of hardware when designing parallelism solutions. This increase in variety indicates the need for finer-grained primitives than what high-level collective APIs offers today. Just as Triton allows average users to modify matmuls for their needs (fusion, quantization, etc.), we hope that SymmetricMemory will enable average users to modify NVLink communication algorithms for their requirements, whether it’s implementing alternate collective algorithms (one-shot allreduce), using different quantization approaches (stochastic rounding), or fusing collectives with other kernels (all-gather interleaved with matmuls).
Relevant Hardware Capabilities
Peer Memory Access over NVLink (via SM or Copy Engine)
NVLinks are effectively a bridge between XBARs. They enable a GPU to access the HBM of another connected GPU either via SM memory instructions (e.g., ld/st/atom/red/multimem, etc.) or copy engines. Both methods use virtual addressing to reference operands.

Figure 1: Source: NVSWITCH AND DGX-2
The CUDA driver exposes this capability through virtual memory management. A GPU can access remote memory by mapping the corresponding physical allocation onto its virtual address space.

Figure 2: Memory mapping for peer memory access over NVLink
NVLS (Multicast and In-Switch Reduction)
Since NVSwitch V3, a GPU can initiate multicast and in-switch reduction by issuing multimem instructions on multicast addresses. The capability allows broadcast and reduce (hence all-gather and all-reduce) to be performed with less NVLink traffic while offloading reduction to the switch.

Figure 3: Broadcast with NVLS

FIgure 4: Reduce with NVLS
The CUDA driver exposes this capability through the multicast mechanism. A GPU can create a multicast address by binding physical allocations from multiple devices to a multicast object and map it onto its virtual memory address space.

Figure 5: Memory mapping for NVLS
SymmetricMemory
Configuring the memory mapping required for the aforementioned hardware capabilities requires some elbow grease and less common knowledge. While some power users can navigate through the setup process, it becomes a hurdle for more engineers to experiment with and implement their ideas.

Figure 6: Configuration process for peer memory access over NVLink

Figure 7: Configuration process for NVLS
Thus, we introduced SymmetricMemory. Semantically, it allows allocations from different devices to be grouped into a symmetric memory allocation. Using the symmetric memory handle, a GPU can access the associated peer allocations through their virtual memory addresses or the multicast address.
SymmetricMemory simplifies the setup process into two steps. First, the user allocates a tensor with symm_mem.empty(). It has identical semantics to torch.empty() but uses a special allocator.

Figure 8: symm_mem.empty()
Then, the user invokes symm_mem.rendezvous() on the tensor in a collective fashion to establish a symmetric memory allocation. This performs the required handle exchange and memory mapping under the hood.

Figure 9: symm_mem.rendezvous()
Remote memory access wouldn’t be useful without synchronization. SymmetricMemory provides CUDA graph-compatible synchronization primitives that operate on the signal pad accompanying each symmetric memory allocation.
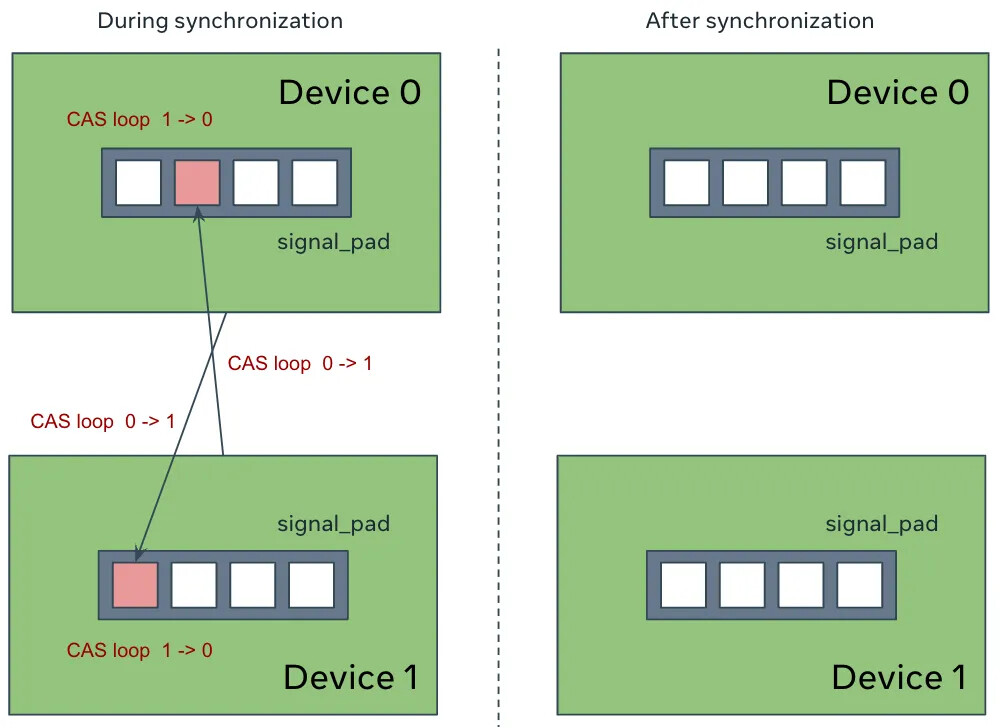
Figure 10: CUDA graph-friendly synchronization primitives that resets the signal pad to 0 upon successful synchronization
Using SymmetricMemory
import os
import torch.distributed as dist
import torch.distributed._symmetric_memory as symm_mem
import torch
rank = int(os.environ["RANK"])
world_size = int(os.environ["WORLD_SIZE"])
torch.cuda.set_device(f"cuda:{rank}")
dist.init_process_group("nccl")
prev_rank = (rank - 1) % world_size
next_rank = (rank + 1) % world_size
# Allocate a tensor
t = symm_mem.empty(4096, device="cuda")
# Establish symmetric memory and obtain the handle
hdl = symm_mem.rendezvous(t, dist.group.WORLD)
peer_buf = hdl.get_buffer(next_rank, t.shape, t.dtype)
# Pull
t.fill_(rank)
hdl.barrier(channel=0)
pulled = torch.empty_like(t)
pulled.copy_(peer_buf)
hdl.barrier(channel=0)
assert pulled.eq(next_rank).all()
# Push
hdl.barrier(channel=0)
to_push = torch.full_like(t, rank)
peer_buf.copy_(to_push)
hdl.barrier(channel=0)
assert t.eq(prev_rank).all()
# Direct
t.fill_(rank)
hdl.barrier(channel=0)
torch.add(peer_buf, rank, out=peer_buf)
hdl.barrier(channel=0)
assert t.eq(rank + prev_rank).all()
# Raw pointers for CUDA/Triton kernels
hdl.buffer_ptrs
hdl.multicast_ptr
hdl.signal_pad_ptrs
Application Examples and Recipes
We’ve been dogfooding SymmetricMemory to test its flexibility and expressiveness by developing PT-D features utilizing it and creating recipes for it. We briefly cover examples in this section.
Decomposition-Based Async-TP (with Host APIs Only)
We implemented decomposition-based async-TP using the SymmetricMemory host APIs. It implements the algorithm proposed in the LoopedCollectiveEinsum paper and leverages key CUDA optimizations from xformers’ implementation. The implementation achieves near-optimal performance for medium and large problem sizes. It is available in PyTorch in an experimental state.
For more details, see [Distributed w/ TorchTitan] Introducing Async Tensor Parallelism in PyTorch.

Figure 11: TorchTitan Llama3 70B profiling trace comparison between the baseline and decomposition-based async-TP
Single Compute Kernel Async-TP (with CUTLASS)
The decomposition-based async-TP suffers from GPU scheduling overhead when the problem size is small. To address this, we implemented a CUTLASS-based, communication-aware matmul. Instead of decomposing the matmul, it rasterizes the blocks in the order the all-gather chunks are ready. This implementation leverages SymmetricMemory host APIs for efficient P2P copies and the stream_write_value32 API for efficient signaling.
For more details, see the PR.

Figure 12: Profiling trace of single compute kernel async-TP w/ CUTLASS
Single Compute Kernel Async-TP (w/ Triton)
As an exploration, we also implemented communication-aware matmul in Triton and achieved good results. This implementation gives users greater flexibility in tuning and epilogue fusion. We published it as a recipe on GitHub.
For more details, see the recipe.

Figure 13: The Triton implementation leverages both the overlapping technique and Triton’s better performance on certain problem sizes
Low-Latency/NVLS Collectives (with CUDA and Triton)
We implemented a set of low-latency collectives commonly used in distributed inference within an NVLink domain (e.g., one_shot_all_reduce, two_shot_all_reduce) and NVLS collectives (e.g., multimem_all_reduce, multimem_all_gather) that are generally superior when NVSwitch V3+ is available. The ops receive symmetric memory tensors as input, and the underlying kernels directly operate on the buffer/signal_pad pointers. These ops are available in PyTorch in an experimental state.
We also implemented the same algorithms in Triton with comparable or even better performance. The Triton implementation gives users more flexibility in prologue/epilogue fusion. We published them as recipes on GitHub.
For more details, see the recipe.

Figure 14: trition_one_shot_all_reduce vs. nccl_ring

Figure 15: trition_multimem_all_reduce vs. nccl_ring

Figure 16: The Trition NVLS all-reduce kernel. It can be easily understood and customized
Low-Contention All-Gather/Reduce-Scatter (with Host APIs Only)
We’ve also experimented with copy engine-based, low-contention all-gather and reduce-scatter implementations. The low-contention implementations leave more SM resources for ambient matmul kernels, at the cost of being slightly slower. In certain cases, the combined effect results in better overall performance (NOTE: NVLS collectives are likely strictly better when NVSwitch V3+ is available)
For more details, see low-contention collectives.

Figure 17: TorchTitan Llama3 70B profiling trace (TP backward) comparison between NCCL all-gather and low-contention all-gather
Feel free to reach out for more information on the implementation or benchmarks, or if you’d like to know whether SymmetricMemory can help optimize your use cases.