Hello there. The main motivator of this discussion is:
- Questionable profile results for FSDP which led to
- Ke W. + Alban D. + Andrew G. discussing solutions which led to
- my benefiting from Alban’s takeaways which hopefully leads to
- your learning more about how the PyTorch CUDACachingAllocator works + how the multistreamness of FSDP makes it all complicated.
Disclaimer: For this note, we will be focusing on the multistreamness of FSDP and ignoring most other details–e.g., we will assume explicit prefetching is disabled and we will only be diagramming the forward case (hopefully WLOG).
FSDP Basics & Rate Limiter (Boo #1)
Let’s start with some ground facts about FSDP. FSDP works on layers at a time and enables perf wins by overlapping the data-fetching part of the next layer with the computation of the current layer. This overlap means that the data-fetching (or the all-gather of the parameters) can be “hidden” and therefore seems to occur without cost. Enabling this overlap requires using at least a computation stream and a separate communication stream, and the most rudimentary model looks like this:

Ideally, the communication stream always fetches data at least one layer ahead so that the computation stream is always busy. This eagerness is desirable–it signifies the CPU is able to run ahead and schedule more things. We like when the CPU is able to run ahead.
BUT! There’s a memory constraint! The whole point of using FSDP is because you cannot fit all your params in one machine.

There’s a big risk that your workload will just go out of memory (OOM) from trying to fit too many things. When communication prefetching is too eager, it is taking more bites than FSDP can chew and soon its mouth becomes too full and no chewing can happen at all.
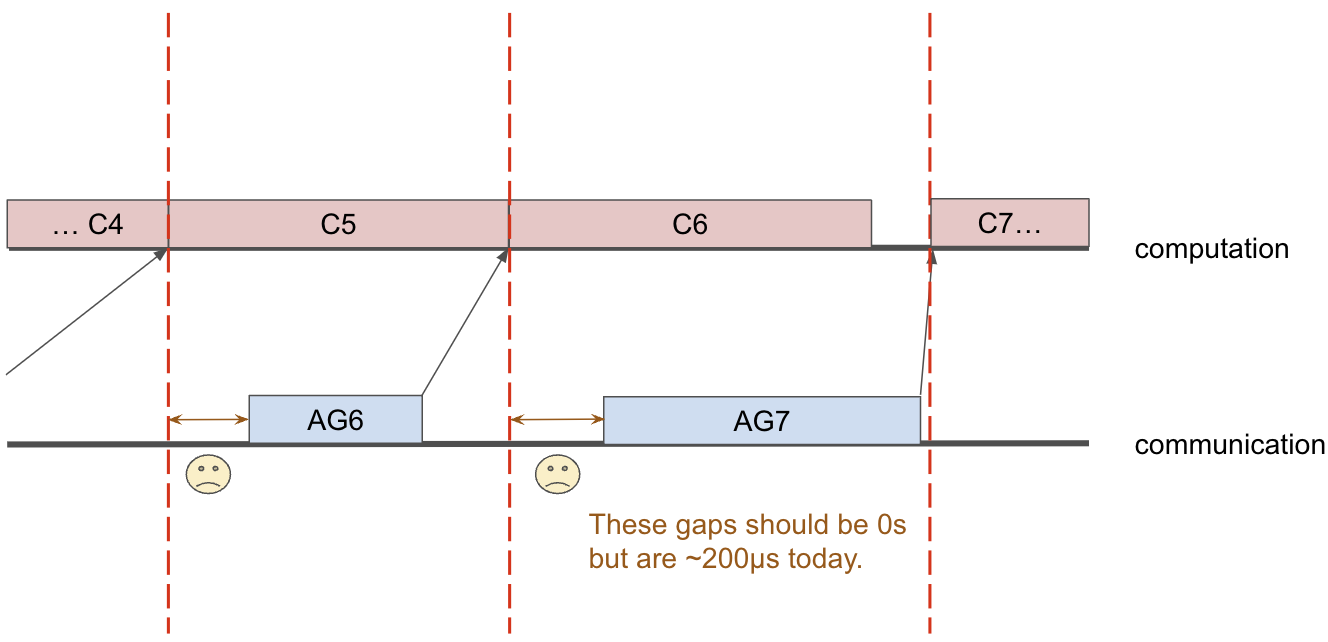
To prevent not being able to keep chewing (OOMs), FSDP enforces a rate limit on how many layers can exist concurrently, and the limit is currently 2. Thus, the communication stream always fetches data at most one layer ahead.

And in a perfect world, the next allgather should start right when the previous layer is done, but, in practice, there is ~200µs of gap due to literally just overhead on the CPU. In other words, once the CPU gets the signal that the previous layer is done, it still needs to do some setup to prepare for all-gathering the next layer’s parameters, meaning precious time on the GPU is wasted. Boo.
FSDP Interesting Profiling Result (Boo #2)
Another unrelated but equally important boo is this interesting profiling result. Take a look–does anything stand out to you? Maybe those pointy spikes standing taller than the rest?

To be absolutely clear, we are expecting something more like:

When we zoom in on the spires, we see memory build up even after a previous layer is done and its memory should be freed, but only for a little time. Very soon after, the memory seems to be jolted from a nap–it realizes it could be freed and frees a lot at once. More technically speaking, memory is requested to be freed at the end of a layer, but there is a small time gap when that memory is not yet freed but the new layer has started needing memory.

If you’re wondering any or all of the following, you are thinking along the right direction:
- “why is there a gap between when a free is requested vs when it’s completed?”
- “max memory usage shouldn’t be bottlenecked by spikes! a lot of memory capacity is currently wasted!”
- “ahhhh this must be the diagram of somebody debugging an OOM on a smaller batch”
- “but seriously, why isn’t the memory freed immediately when the layer’s done?”
Keep both booeyness in mind as we switch gears to understanding our PyTorch CUDACachingAllocator. We’ll start with a simple model and build up gradually, and, by the end, hopefully satiate some of your curiosity.
Since we will talk a lot about freeing memory, I will attempt to be precise by using the following terminology:
- free: the user facing call when a Tensor is deleted
cudaFree(): the call into the CUDA API for releasing GPU memory- blockFree: not a real API; refers to when our CUDACachingAllocator considers a block as freed and reusable.
V1: Single-stream-no-nonsense CUDACachingAllocator
It suffices to start with its name. CUDA - ah, we are working with CUDA memory (vs CPU). Caching - so there’s some sort of caching involved, we’ll get to it soon. Allocator - I guess we handle the allocation and freeing of memory. Put all together: the CUDACachingAllocator is PyTorch’s way of interfacing with CUDA memory. It’s special because it will hold on to memory instead of freeing it back to CUDA so that the next time you need memory, it can pull from that cache without making another potentially expensive cudaFree()/cudaMalloc() call.
This amortizes very well normally and is more performant than calling directly into CUDA every time memory is needed. However, there are times when trying to allocate memory will take longer than a cudaMalloc(). For example, when there is poor fragmentation and none of the chunks of reserved memory are big enough to serve the new allocation, the CUDACachingAllocator is forced to cudaFree() all its reserved memory (with empty_cache()) before calling cudaMalloc():

Calling empty_cache() is expensive due to cudaFree() triggering a synchronization between all the streams on the device, which is why people should avoid fragmentation as much as possible. When memory is well managed, our CUDACachingAllocator is so reliable that people normally never have to think about it when they run PyTorch.
Disclaimer: my illustration above is an oversimplified view where the CUDACachingAllocator seems to work on one long block of CUDA memory. In actuality, the CUDACachingAllocator works on memory in varying-sized blocks with some additional complexity for releasing memory. Moreover, you might be wondering if the memory for C, E, G, and I got reallocated in order to be condensed. Nope! They are still at their places in memory. Rather, when the allocator calls cudaMalloc() for J, CUDA will virtually map noncontiguous physical memory to contiguous blocks of virtual memory. The reason I drew it condensed is to show that the CUDACachingAllocator no longer has any cached blocks at the end.
V2: Introducing CUDA streams
Let’s peek a little lower. CUDA allows parallelizing computation through streams, though the general vibe with streams is that they are tricky to get correct–and if you’re looking for parallelism wins, you should consider that GPUs are already designed for parallelism and maximize there. Hence, for simplicity and sanity, PyTorch uses one stream for everything which is our default stream.
I think of streams as queues of tasks. The machine will tack your desired computation onto the queue of the stream you specified. Streams can be scheduled at the same time if they’re independent, or, in other words, they need different parts of the physical data (e.g., the memory controller getting data from the CPU vs the SMs doing compute on some unrelated data).
There is a single memory space that all streams can access, which is convenient but can be dangerous! For internal correctness and simplicity of implementation, our CUDACachingAllocator, when allocating Tensors, will tag that block of memory with the stream that made the request. With this metadata, one can verify when executing kernels that only Tensors on the same stream can be used together. This invariant has benefits! Since we are only able to control the order of operations within a stream and NOT across streams, we are able to get safety and performance through our CUDACachingAllocator.
Consider a workload where we allocate some memory A, use it in computation, and then free it in order to reuse that memory for another Tensor C. Here’s how the single-stream model would look like if we had no CUDACachingAllocator and just directly interfaced with CUDA:

This workload is definitely safe, but we lose performance when the CPU must be sync’d with the GPU and wait for A + B to be done before cudaFree()’ing A. When the CPU is forced to wait, the next GPU kernel launch is consequently forced to wait, meaning there will be larger gaps in GPU usage as well.
On the contrary, when we allow the CUDACachingAllocator to manage the memory for us, we avoid a CPU-GPU sync. We then enable the CPU to “get ahead” of the GPU–this allows us to hide overhead and in turn maximize GPU usage. By the way, the concept of having the CPU get ahead is a huge theme in performance optimization. Don’t forget it.

Note that when the CPU does del A is NOT when A’s memory can be considered reusable from anywhere (that would be disastrous). We can instead logically think of allocations and blockFrees as “usages” of the memory associated with streams, just like kernel launches. Since PyTorch operates on one stream, we can trust that the order of operations will be queued correctly on the stream. For example, if we wanted to access/peek at C after malloc C from the CPU, the stream would insert that request after A is blockFreed and C is ready to go.
This sense of safety applies to single streams only! For example, if you enqueued a task onto a different stream to peek at C, it IS likely you may access the contents of A instead of C because there’s no guarantee of synchronization across streams. You would have to manually synchronize–this is part of why streams are unsafe!
One effect of the CUDACachingAllocator tagging blocks by stream is that the blocks will keep that tag during its entire lifetime. When a request for memory comes in from a certain stream, the CUDACachingAllocator will first give out blocks with the same stream tag if available. If not available…well…this is another reason the CUDACachingAllocator would need to cudaFree() and reallocate memory (which, if you recall, is slow). Even if you have enough memory on the machine, if it’s tied to a different stream, our CUDACachingAllocator will cudaFree() its reserved memory to reallocate for your particular stream. Again, this problem is only relevant when multiple streams are used. In the default PyTorch case, you should not run into this as everything uses a single stream.
V3: Stream Synchronization
It is time to address the cross stream case. In V2, we discussed having multiple streams but we did not talk about mingling the streams. Instead, we mentioned how each stream is meant to safely keep to itself through our CUDACachingAllocator tagging memory with streams. We will soon get there, but, first, let’s familiarize some terminology.
“How life works is you have events, and you just wait for the events to happen.” - Alban Desmaison (08.18.2023)
The following workload schedules events on stream 0 and has stream 1 and the CPU wait for the events. Keep in mind the happenings of the events below can shift left or right based on the queue situation in the streams.

Tasks that need to happen are denoted as events, and calling wait() on those events for a particular stream or CPU will trigger a blocking wait on the stream or CPU. For example, in the diagram above, stream 1 cannot run any computation once it is called to wait for Ev1 until the event completes in stream 0. Likewise, the CPU is blocked and cannot run anything once it is called to wait for Ev2 until the second event completes. Minor tinkling of alarm bells should occur in your brain if you’ve remembered our general perf theme of “letting the CPU get ahead as much as possible”. Blocking the CPU is exactly the opposite of letting it get ahead! We should be minimizing blocking the CPU as much as possible. For the purpose of illustrating the blocking waits, I had drawn the events above as if they take a long time, but they are usually very short and are created in conjunction with other kernels to schedule synchronization. The following example should help clarify.
Alllll right. Study the following workload:
- we designate
Ato S0 - we compute
A *= 2on S0 - create an event Ev on stream 0 (if you’re using PyTorch’s API, you should
recordit on s0 as well for technicality) - we ask S1 to
waitfor Ev to force it to wait for A’s computation - we compute
B = A * 3on S1 - we’re done with
Aso we deleteA
What could go wrong?

Did you figure out what could go wrong yet? Don’t read on if you want some more time to ruminate.
Okay, time’s up! The issue: A is considered deleted but we still need it for B = A * 3 on stream 1! Oh no! If we allocate more data on stream 0 after, that data may unsafely reuse the memory of A and the result of B will be all messed up! Recall that there is no automatic synchronization across streams. Our single-stream invariant of everything queuing up in order no longer holds in this world…
…but in comes our hero record_stream()!
With the Tensor.record_stream(stream) API, the CUDACachingAllocator provides a way to synchronize across streams. record_stream() adds metadata associated with the memory of A to prevent it from getting del’d if another stream still needs A. A’s memory will be kept active until stream 1 has completed B = A * 3.

record_stream() is the only reason why a requested free is not immediately blockFreed. (Does this remind you of a profile we had mentioned earlier?) It is important to note that, with our CUDACachingAllocator, del doesn’t literally blockFree anything. It is only during a later malloc where our CUDACachingAllocator has to evaluate whether a block of memory can be reused. Consider the following allocations of C and E.

When the CUDACachingAllocator sees the request for allocating C, it knows that the memory of A cannot be blockFreed yet, so it will either serve C with another cached block or cudaMalloc() new memory and, in the worst case, trigger a cudaFree() if there’s insufficient memory. On the other hand, by the time the request for allocating E rolls around, the CUDACachingAllocator observes that no more streams are using A so it can reuse A’s memory. From the CPU or user perspective, this is nondeterministic! You have no idea when A can be blockFreed so you do not know whether malloc C, E, or whatever will need new memory or just reuse A’s memory.
This nondeterminism is no bueno, because the onus is now on the user/CPU to do the guesswork in avoiding large spikes/OOMs. You can imagine that the CPU would ideally want to know when A’s been blockFreed before it starts new allocations. The safest way to do this is with a CPU sync…which…we should all know by now is unideal for perf.
We are about to dive into FSDP, which means the diagrams are going to get complicated. For simplicity, I will no longer be explicitly drawing the event creation after kernels. Instead, I will lump the kernel + event as one box and signify which kernel is intended to be waited for. In the diagrams, instead of:

You will see:

Bringing FSDP back into the picture
Why did we talk so much about multiple streams when basic PyTorch only uses a single stream? Well, FSDP needs at least one other stream for the communication collectives (the allgathers). So…FSDP oversimplified (and wrong, but this is a good thought exercise anyway):

The above diagram, while much simpler than actual FSDP, can certainly be confusing, so let’s break it down. First, we notice that FSDP always enqueues instructions in the following order for each layer i:
- allgather layer i
- tell the computation stream to wait for the params to be ready
- compute layer i
- use record_stream to prevent i’s memory from getting reused incorrectly
- delete layer i
Feel free to take some time and follow the arrows, ascertaining that the computation and communication are indeed logically overlapped. When your brain is satisfied, notice the sad face and try to reason through why a spike may happen here.
Since allgather i+2 can nondeterministically overlap with when the memory for layer i can be considered blockFreed, the allgather i+2 will use a new block of memory if it happens before layer i’s memory is blockFreed, leading to a big jump in active memory usage. Later on, once more computations need memory for intermediates, the CUDACachingAllocator will notice the memory for layer i can be blockFreed and start blockFreeing all of it. Maybe it’s something like:

If that makes sense, good. If you’re raising your eyebrows, that’s good too, because I’m going to have to tell you that I lied and the oversimplified FSDP diagram was wrong. How come?
- There are actually 2 (not 1) communication streams, NCCL and allgather, who work together to make everything sync properly. This fact does not make a big difference to our understanding, but if you’re curious about the hard truth, you can ask us later (;
- More glaringly, I didn’t include the FSDP rate limiter! You would recall that the FSDP rate limiter is a CPU side sync that would prevent
allgather i+2from happening until layer i was all blockFreed. Thus, the diagram with the rate limiter in action would look like:

Your immediate reaction is probably: “so then wouldn’t the spike we just talked about not happen?”
And indeed you would be correct! The FSDP rate limiter does successfully prevent the spikes in the forward passes by preventing that overlap. It instead uses a CPU sync to ascertain that layer i’s memory is all blockFreed before allocating memory for layer i+2. However, behold that all the spikes occur in the backward, where stream interaction with the autograd engine gets a lot more dicey and it’s not just FSDP allgathers that need to be synchronized.

Naturally, you would wonder why the FSDP rate limiter doesn’t work the same way with the backward pass. I will admit I am not the person who knows the most details here (talk to Andrew or Ke), but my understanding is that the FSDP rate limiter was designed to work with mainly FSDP collectives, and if other stream ops get enqueued (e.g., by the autograd engine), synchronization can get weird.
Consider the following allocations that are coming from the autograd engine and not FSDP below.

Since the mallocs nondeterministically overlap with when the memory for layer i is blockFreed, the autograd mallocs will start racking up more memory before, suddenly, one of the mallocs causes the CUDACachingAllocator to realize layer i’s memory can be blockFreed and starts blockFreeing everything. That was a long sentence–if you didn’t find it confusing, skip the next two paragraphs. Otherwise, imagine that the allocations are, in essence:
malloc a
malloc b
malloc c
…
malloc s
malloc t
malloc u ← when layer i is blockFreed
malloc v
…
The first 20 mallocs (from a to t) will not be able to reuse i’s memory and will thus incur new active memory. On malloc u, the 21st malloc, the CUDACachingAllocator will see that all of i’s memory can be reused! It will then start reusing that memory and counting it as blockFreed. For visualization purposes:

Well this is unfortunate: it looks like we need more synchronization. Maybe we should add something like the FSDP rate limiter to deal with the autograd engine…
Or should we? Remember, the FSDP rate limiter is a CPU sync! A perf killer, that one!
A Proposal: Stop burdening the CPU
FSDP is saying no to CPU syncs! Rather than placing the burden on the CPU of needing to sync on when memory can be cleared (the current case with record_stream, del, and the rate limiter), the proposed solution is to shift that burden to the communication stream instead. How?
- No more
record_stream - No more CPU sync from rate limiter
- Delay the
delto after the next layer - We still need to synchronize somehow–add a stream to stream sync through queuing and waiting for an event!
Put altogether:

Effectively, we replace the need for a CPU sync with a stream - stream sync through enqueuing event i after layer i. Before we delete i’s memory, we add a wait for this event to ensure that layer i has completed. This allows the CPU to get ahead and relaxes the need for a sync to ascertain whether a layer’s memory could be blockFreed. We let the streams sync among themselves.
Hence, it is key to delay the del i to be after layer i+1’s compute has been scheduled so that the communication stream could get some work in (allgathering the next layer) before being forced to busy-wait for event i. Otherwise, we would be disabling the parallelizing power of overlapping communication with computation, and we might as well revert back to a single stream model!
Both these changes work together in unsubscribing the CPU from handling the nondeterminism regarding when memory could actually be blockFreed. By having the streams figure out when they need to block and wait, our CPU can carefreely skip along and keep scheduling tasks, whether the tasks are from the autograd engine or FSDP or something else entirely. While we hope for this proposal to help improve FSDP perf and memory usage, we know it is sadly NOT guaranteed that the spikes will now disappear. There are simply too many issues going on to fit into one note, and some problems remain uninvestigated. One thing we do know is that the autograd engine, especially when using activations checkpointing, may insert record_streams itself that will muck with our record_stream-free system. This, on top of all the other weird stream stuff autograd may do, will disturb our peace and should be looked into eventually.
Acknowledgements
Thanks @albanD for being the main offloader of knowledge + for answering my questions at every turn,
Thanks @colesbury for fact-checking the CUDACachingAllocator parts,
Thanks Ke Wen for reviewing the content and thanks @awgu for verifying the order of CPU instructions in the FSDP diagrams,
Thanks @mikaylagawarecki for offering to read over the note to ensure everything made sense,
And, of course, thank you for reading~