I’m currently working on benchmarking TorchInductor’s optimization impact by selectively disabling various fusion and scheduling passes. So far, I have:
With these changes, I now want to focus specifically on CPP & Tritoncodegen fusions — the ones happening during kernel generation in Inductor after the scheduler.
My goal is to:
Generate one kernel per node/operation (instead of fused multi-op kernels).
Understand how much these codegen-specific fusions contribute to TorchInductor’s overall performance gains, compared to other optimizations like scheduling and inlining.
Questions:
How can I disable codegen fusions entirely so that TorchInductor generates one kernel per node/operation instead of fusing multiple ops? (Are there any flags?)
How much do these codegen-specific fusions contribute to TorchInductor’s overall performance? (Were codegen fusions part of the “fusion” performance speedups reported in the PyTorch 2.0 paper?)
Thanks for the response! I think I may not have framed my question clearly before, so let me clarify.
I’ve already disabled scheduler fusions (e.g., via can_fuse and related heuristics) and also disabled inlining optimizations.
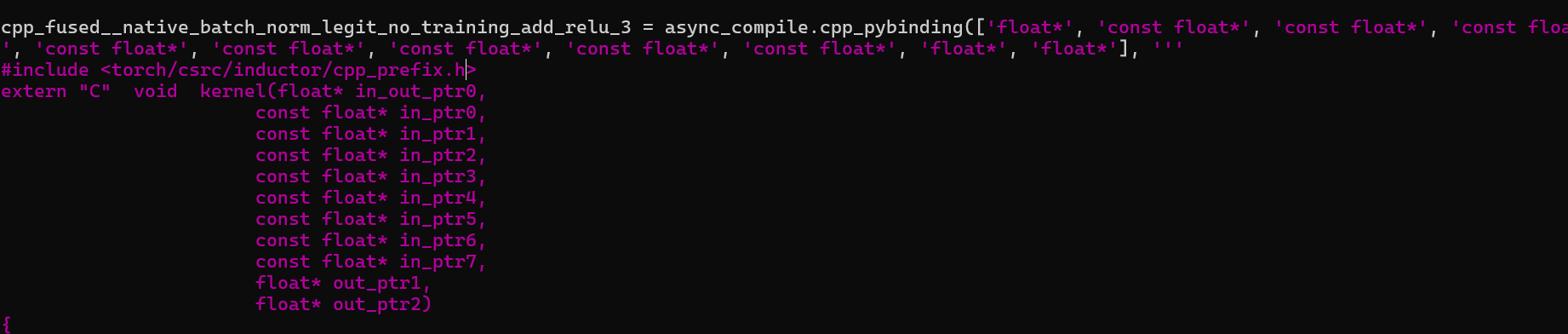
However, I’m noticing that even with scheduler fusions disabled, some generated kernels still contain multiple operations.
E.g. in the output_code.py file I still see a function called cpp_fused__native_batch_norm_legit_no_training_add_relu_3, this suggests that multiple ops (batch_norm, max_pool2d, relu) are still being fused inside the generated C++ kernel, even though I’ve disabled all scheduler fusions.
I’m trying to quantify the contribution of each optimization stage in TorchInductor — to understand their individual impact on TorchInductor’s performance.
So I wanted to confirm a couple of things:
Are there fusions/optimizations happening in torch/_inductor/codegen/cpp.py or triton.py that are separate from scheduler fusions? Can I get down to one OP per Kernel?
In the PyTorch 2.0 paper, were these potential fusions included when reporting the performance speedups?
If that fixes it then those weren’t fusions, it is just a quirk of how the C++ backend does function boundaries to avoid creating a new omp for blocks. For C++ a fusion would produce a single loop, while that would produce two.