Overview
I recently spent some time looking into import torch time, sharing some learnings from this.
Python provides an environment variable, PROFILE_IMPORT_TIME , that will give the breakdown of how long each import takes.
PYTHONPROFILEIMPORTTIME=1 python -c "import torch;" 2> import_torch_profile.txt
The output timings are visualized with tuna below. Note that the diagram is left-heavy, that is, the longest import within each package is on the left.

From the above, we can see that the top 10 modules by import time are
-
torch._C(41.1%) -
torch._meta_registrations(18.9%)- imports
decomps,refs,prims,_custom_op.impl
- imports
-
torch._masked(16.3%)- first module to import
sympy(15.8%)
- first module to import
-
torch.functional(4.3%) -
torch.export(3.2%) -
torch.quantization(2.1%) -
torch.utils.data(1.1%) -
torch.hub(1.1%) -
torch.optim(1.0%) -
torch.distributions(0.7%)
We can also see that the sympy (15.8%) and numpy imports (6.3%) are the external imports that take up the most time, totaling around 22% of the import time.
Registrations to the dispatcher
Operators and operator schemas are registered to the dispatcher at static initialization time during import torch. We can visualize this by using py-spy with the --native option to obtain the C++ stack traces for import torch.
py-spy record -o profile.speedscope -f speedscope --native -r 2000 -- python -c "import torch;"
Note that since py-spy pauses the process while collecting samples, the timings in the profile are distorted. However, we can see from the profile that the C++ registrations to the dispatcher are the bulk of the torch._C import.
Zooming in on what happens within each _GLOBAL__sub_I_Register{*}.cpp, we can see many consecutive impl or def calls mirroring the m.impl and m.def that a TORCH_LIBRARY(_IMPL) macro takes.

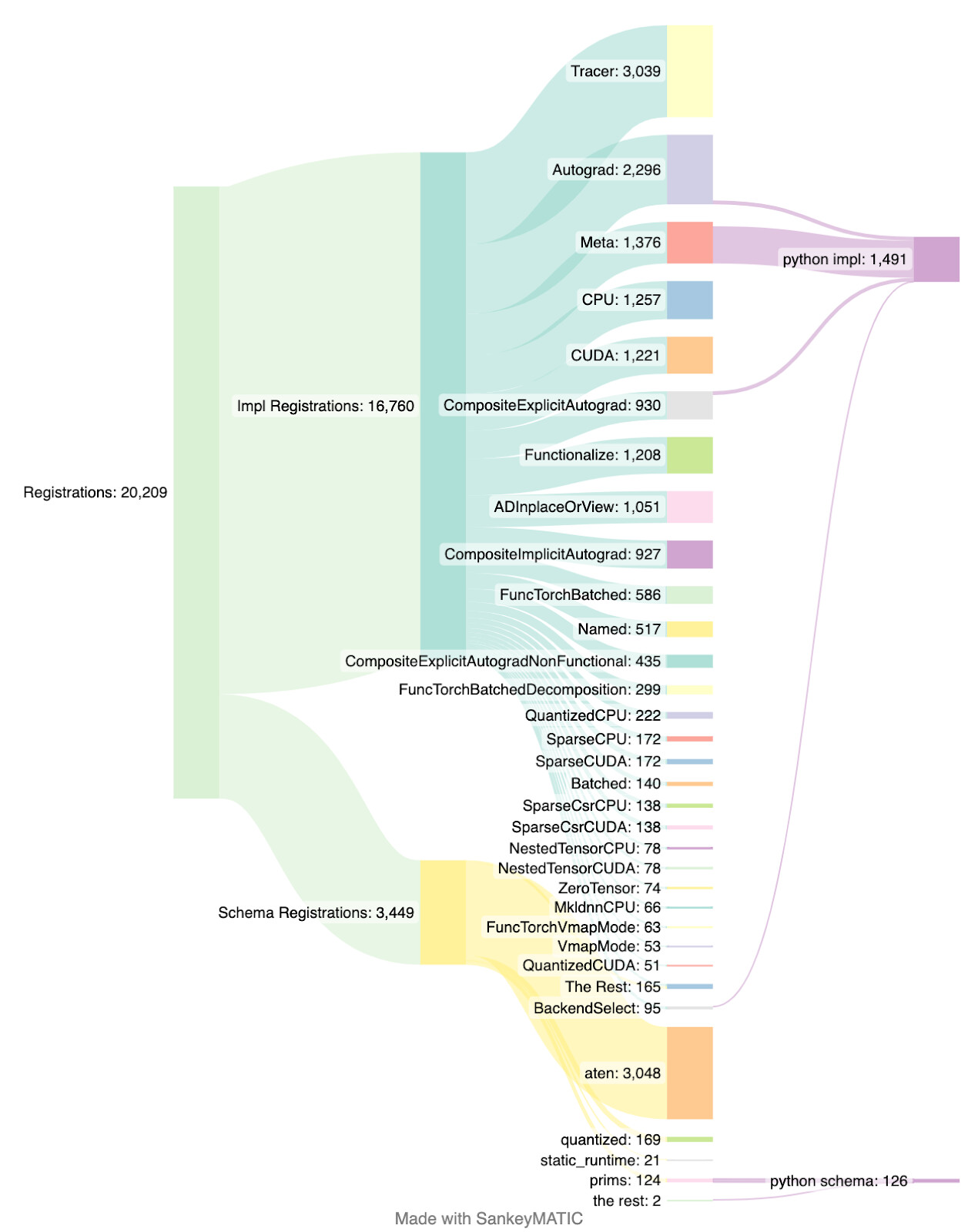
Registrations to the dispatcher can be done via both C++ (e.g. TORCH_LIBRARY_{*} macros which correspond to the _GLOBAL__sub_I_Register*.cpp above) and via python (e.g. python meta registrations using torch.library). To understand the breakdown of registrations between C++ and python, the following diagram contains a breakdown of schema and operator registrations as well as the number of these that are registered via python generated via this gist.
Effect of lazy imports
In #104368, PEP 562 was used to make the torch/_dynamo and torch/_inductor imports lazy. More recently, the torch/onnx and torch/_export imports were also made lazy. We can see the corresponding time breakdown when these imports are not lazy below

Conclusion
This post gave an overview of what happens when you import torch. If you have ideas or want to help reduce / monitor this, please reach out!
Note: The above analysis was done using an install of the 2.1.0 release binary on an Intel Xeon Platinum 8339HC.
